
Это статья — адаптация изначальной версии доклада на Стачку 2025 нашего директора по продукту Юлии Федотовой. От этой версии модератор секции пришёл в ужас, так как все расчёты были расписаны максимально детально, а количество графиков стремилось к бесконечности. Если вам интересно ознакомиться подробно со всеми формулами, расчётами и графиками, а также узнать больше про то, как работает поиск в Яндексе, — эта статья для вас.
Коротко про Топвизор
Топвизор — это платформа поисковой аналитики для SEO‑специалистов, маркетологов и digital‑агентств. Многие знакомы с нами как с сервисом для проверки позиций, но на самом деле Топвизор — это целая онлайн‑платформа с более чем 12 инструментами для работы с семантикой, поиска ошибок на сайте, анализа и парсинга конкурентов и много другого.
В 2024 году Топвизор получил премию #BDD и был признан лучшим сервисом для измерения позиций на конференции Baltic Digital Days. А ещё у нас самый милый маскот, которого недавно ещё и связали!
Как мы докатились до жизни такой…
Наша Поддержка часто сталкивается с обращениями про то, что «Топвизор врёт». Иногда нам пишут, что «сервис снимает неправильные позиции». Поэтому родился доклад для Стачки и эта статья, чтобы наглядно показать, кто врёт и врёт ли кто‑то вообще. Пристёгивайтесь! Будем разбираться в различиях между Яндекс Search API и «живой» SERP‑выдачей.

В начале было Слово, и Слово было XML
Начнём с того, как вообще в Топвизоре работает проверка позиций в Яндексе. Вопросы наших пользователей доказывают, что этот момент нужно пояснить подробнее.
Вернёмся немного в прошлое. Всё началось со слова на три буквы — XML. Яндекс XML был официальным сервисом Яндекса, который позволял получать результаты поиска. С помощью XML получать список сайтов по запросам и проверять по нему позиции можно было бесплатно и без капч — а значит довольно быстро и легально (вообще парсить поиск — это не то чтобы законно). А если ты парсил «живые» результаты выдачи, то получал капчу.
Конечно, там были ограничения. Каждому вебмастеру предоставлялись лимиты. Лимиты были по часам на количество запросов, но, главное, была киллер фича — возможность передавать лимиты на другие аккаунты. И именно их можно было передавать пользователю topvisor. Когда вы их передавали, мы получали лимиты, а вы — скидку на проверку позиций.
SERP или «живая» выдача
Что же такое SERP‑выдача? Яндекс SERP (Search Engine Results Page) или «живая» выдача — это то, чем реальные люди пользуются во время поиска. На первый взгляд кажется, что парсинг бесплатен, любой же может вбить какой‑то запрос в Яндекс и получить результат.
Но ты платишь за количество страниц, которые получаешь. Например, мы хотим проверить позицию сайта среди 100 сайтов. В XML мы делаем один запрос, забираем всю сотню и ищем среди них нужный сайт. А в SERP мы получаем за один запрос 10 сайтов, следовательно, чтобы забрать 100 сайтов, надо сделать 10 запросов. Поэтому, если мы хотим получить ТОП‑100, парсинг SERP дороже парсинга XML в 10 раз. А ТОП‑100 это стандартная глубина проверки во всех сервисах проверки позиций.

А ещё когда Яндекс парсит робот, он получает очень много капч. Цены на капчи доходят до 200‑300 рублей за 1000 сложных капч, то есть до 20‑30 копеек за 1 капчу. И если у вас одна капча в час, это отлично, но если Яндекс стал капчевать ваши IP — ваши дела плохи.
По словам Яндекса, это было сделано из‑за того, что numdoc «оказывал чрезмерную нагрузку на поисковую инфраструктуру, осложнял работу поисковой системы и повышал риск недобросовестного влияния на ее функционирование». Простыми словами, это было сделано для борьбы с парсингом.
Тот же процесс идёт в Google. Прямо во время финальных прогонов доклада Google отключил параметр num, который позволял получать 100 результатов за запрос. Теперь даже с этим параметром num Google отдает 10 результатов. То есть чтобы проверить позицию сайта среди 100 сайтов, приходится делать в 10 раз больше запросов: 10 по 10 вместо 1 запроса к выдаче. Из‑за развития нейросетей и борьбы между корпорациями за обучение LLM на своих ресурсах мы наверняка услышим ещё не одну новость, связанную с ужесточением борьбы с парсингом.
Также важно учесть, что необходимость разгадывать капчу напрямую влияет на скорость. Поэтому данный метод гораздо медленнее по сравнению с XML.
У нас SERP всегда был подключен про запас. Но мы подключали его ситуативно, при необходимости. Как правило, нам хватало и обычного XML.
Всё это очень интересно, но совпадали ли в XML и SERP позиции?
Но вам, как нашим пользователям, наверняка гораздо интереснее ответ на вопрос, а совпадали ли там в итоги позиции или как? Наш опыт говорит о том, что в основном они совпадали, не считая редких исключений.
Да, формально это разные технологии. И ответ от XML — это не парсинг «живой» SERP‑выдачи. Но мы в Топвизоре всегда детально анализировали каждое обращение о том, что позиции не совпадают, а таких всегда было минимум несколько в сутки, и во время анализа каждого мы проводили десятки проверок и тестов.

Но проверил позицию в выдаче он всего 1 раз! А поддержка Топвизора проверяет позицию в живой выдаче многократно, и выходит так, что пользователь, например, увидел сайт на 30 позиции. А мы увидели сайт 10 раз на 3‑ей позиции, 10 раз на 30‑й позиции и 10 раз на 100‑й. То есть проверка Топвизора через Yandex Search API выдаёт верную позицию, но не для 100% случаев.
Но верной позиции нет и в самой выдаче! Потому что именно в ней мы и видим этот разброс в позициях, и каждый такой случай мы всегда подтверждаем скриншотами, то есть то, что сайт иногда на 3‑й, а иногда на 30‑й позиции — это не просто наши слова. На какую позицию наш робот «попал», такую и выдал — прямо как увидит сайт и обычный человек.

Предугадать такую ситуацию, не сделав несколько проверок, невозможно. Мы показывали пример, когда сайт и выдачу вот так «штормит», в статье Как объяснить клиенту, почему позиции в Топвизоре не совпадают с выдачей.
А что насчёт «редких исключений»? Да, они есть, и будет нечестно не упомянуть о них.
Но есть и тот самый 0,01%, когда никакого разброса в выдаче нет, просто в SERP одна позиция, а Search API (или ранее — XML) присылает нам другую позицию, и они там стабильны. Например, в SERP сайт всегда на 5 позиции, а при проверке через API — он всегда на 1‑й.
Однако за весь мой период работы в Топвизоре всего было всего 30 таких случаев, и сейчас у нас есть 4 сайта, для которых это актуально (что любопытно, у этих 4‑х сайтов одна тематика — онлайн‑кинотеатры). Что мы делаем в таких ситуациях? Мы на постоянной основе переводим проверку сайта в SERP, несмотря на то что в таком случае работаем в убыток, чтобы вы получали корректные отчёты. Так что вероятность, что ваш сайт действительно столкнулся с такой ситуацией, крайне мала. В нашем сервисе проверяются миллионы сайтов.
Как правило, причины несовпадения позиций у клиентов в отчётах Топвизора и вручную гораздо более тривиальные. Это то, что они не всегда проверяют позиции в инкогнито, выбирают не тот регион, который указан в проекте, или проверяют позицию только 1 раз. Чтобы они корректно проверяли позиции, мы подготовили чек‑лист в этом посте. Скачивайте его и пересылайте своим клиентам, чтобы у них не возникало вопросов по тому, почему позиции отличаются.
Про какой XML вы тут рассказываете? В названии же был Яндекс Search API?
Недавно Яндекс понял, что он отдаёт бесплатно огромное количество данных о поиске, которые другие сервисы продают, и, видимо, посчитал, что это как‑то неразумно. Так что осенью 2023 года Яндекс закрыл сервис Яндекс XML и заменил его на Yandex Search API. По сути, это был тот же самый XML, только платный, и лимиты передавать в нём уже нельзя. Search API даёт те же данные о позициях, по тому же алгоритму, что и XML. Сейчас Топвизор использует для проверок в Яндексе Yandex Search API и в десктопной, и в мобильной выдаче.

Казалось бы, самое время переходить на SERP, но получать данные через SERP становится всё сложнее. Яндекс усложняет капчи, показывает их чаще и быстрее. Также напомним, что SERP за 1 запрос отдаёт 10 результатов, а вот Search API за 1 запрос — 100. Что делает получение ТОП‑100 через SERP в 10 раз дороже, чем через Яндекс Search API.
Мы разобрались в общих чертах, как работает проверка в Топвизоре через SERP и через XML и причём тут Яндекс Search API, так что пора переходить к самому исследованию.
Разрушаем мифы и выдаём базу
В SEO‑среде довольно много мифов относительно проверки позиций через SERP и через API. В первую очередь это связано с тем, что сам Яндекс никогда чётко не говорил, как же работает XML, а также из‑за того, что поиск в принципе работает нестабильно. Отсюда возникли мысли, что это ботовыдача. Якобы XML (а теперь и Yandex Search API) — какая‑то отдельная выдача, а не сам поиск, и некачественной накруткой туда можно «загнать» сайт. А сервисы поисковой аналитики ещё и высокие позиции в отчётах покажут, хотя сайт будет виден только ботам.
Чтобы развеять эти утверждения, мы проверили, действительно ли есть расхождения в ТОПах, если отправить запросы на одновременную проверку в Search API и в SERP, какой амплитуды эти расхождения и что ещё интересного мы сможем узнать. Погнали!
Описание исследования
-
150 запросов разных тематик из Апометра Топвизора.
-
Нет брендовых запросов и запросов с топонимами.
-
Запросы и их частота собраны и актуализированы летом 2025 года.
-
При анализе частоты использовали “!Частоту” по Вордстату в регионе Москва. Кстати, проверять частоту запросов можно в Топвизоре.
-
Запросы разделены на 3 группы: Низкочастотные (НЧ; с “!Частотой” от 1 до 1 000 в месяц), Среднечастотные (СЧ; от 1 001 до 9999 в месяц), Высокочастотные (ВЧ; свыше 10 000 в месяц).
Парсили ТОП‑10 и при анализе учитывали домены, а не точные URL, в регионе Москва, в десктопной выдаче. В итоге у нас получилось около 100 тысяч строк с данными!
Чтобы результаты исследования были достоверными, важно, чтобы набор данных (то есть наши поисковые запросы) был одномерным. Чтобы это проверить, мы построили Q‑Q Plot, или график квантиль‑квантиль (КК).
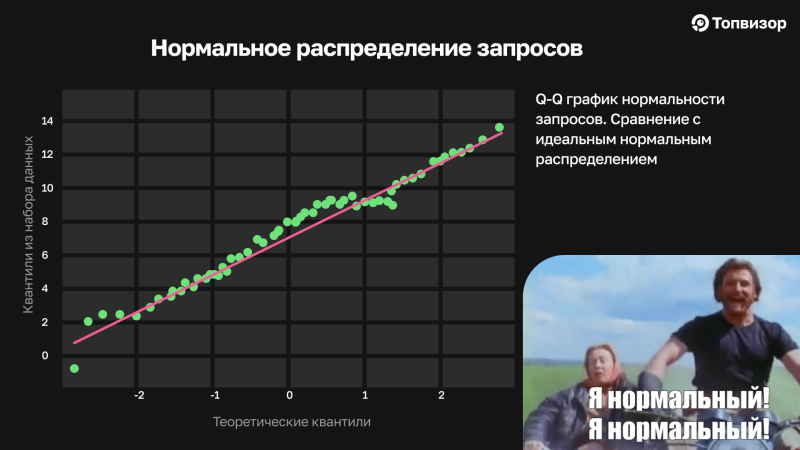
На графике видно, что логарифмы частот поисковых запросов (зелёные точки) расположены очень близко к красной прямой линии теоретического нормального распределения. Это подтверждает, что наша выборка имеет нормальное распределение, что обеспечивает репрезентативность выборки и позволяет равномерно охватить все типы запросов.
На старте исследования мы задали себе следующие вопросы 👇
-
Как отличаются домены в ТОП‑10 между API и SERP, а также внутри одного способа сбора в разных сессиях.
-
Как выдача меняется с течением времени и насколько она стабильна.
-
Влияет ли частота запросов на всё это.
В процессе исследования мы не только нашли ответы на них, но и разрушили парочку мифов.
Миф 1. ВЧ‑запросы штормит сильнее
Наш анализ показал, что это не так. Доказываем ниже на формулах и графиках.
При анализе мы использовали коэффициент Жаккара, который показывает, насколько два множества похожи друг на друга. Он может варьироваться от 0 (множества полностью различны) до 1 (множества полностью идентичны). В нашем случае он будет показывать, насколько похожи друг на друга два ТОПа сайтов (ТОПы — это в данном случае наши множества), то есть сколько они имеют общих доменов.
Формула:
J(A, B) = |A ∩ B| / |A ∪ B|
где:
-
A и B — два сравниваемых набора данных;
-
|A ∩ B| — количество элементов, которые есть и в A, и в B (пересечение);
-
|A ∪ B| — количество всех уникальных элементов, которые есть в A, в B или в обоих наборах (объединение);
-
| | — мощность множества (количество элементов).
Посчитаем коэффициент Жаккара на конкретном примере. Возьмём 2 ТОПа по 10 сайтов. В каждом ТОПе отличаются по 2 сайта. Ниже на картинке элементы одинаковые для обоих множеств обозначены зелёным, а отличные — красным и синим.

В этих ТОПах мощность пересечения будет равна 8 — это одинаковые сайты. А мощность объединения — 12, это уникальные элементы из обоих множеств. И коэффициент получается — 0,67.
Мы ещё не раз встретим в статье коэффициент Жаккара, принимающий значение 0,67‑0,7. Поэтому запомним, что для такого показателя в ТОП‑10 у нас должны совпадать 8 сайтов из 10.
☝️🤓 Чем выше коэффициент Жаккара, тем больше похожи ТОПы между собой.
Для опровержения мифа 1 мы рассчитали коэффициент Жаккара для запросов различной частоты и получили примерно одинаковый результат для каждой группы. Детально данные можно проанализировать с помощью диаграммы Box plot, или «ящик с усами».
Диаграмма состоит из нескольких элементов:
- «Ящик» — 50% всех центральных значений. Показан синим на графиках;
- Медиана — середина ряда (не среднее). Показана зелёным цветом;
- «Усы» — показывают диапазон значений за исключением выбросов. Показаны белыми чёрточками. Внутри усов находятся все статистически значимые значения, которые были получены в процессе исследования;
- Точки — единичные выбросы, которые не имеют статистической значимости в качестве паттерна, однако игнорировать их наличие нельзя, особенно когда мы имеем дело с позициями и ТОПами. Показаны фиолетовым. В нашем случае выбросы — это единичные ТОПы, которые в контексте позиций всё ещё могут быть показаны каким‑то людям, а учитывая, что к поиску обращаются миллионы людей, они могут встречаться какое‑то значимое количество раз в отличие от нашей ограниченной выборки.
На графиках ниже видно, что «ящики» по каждой группе запросов примерно одинаковые — коэффициент Жаккара составляет 0,55‑0,8. Да, у высокочастотников «ящик» и усы немного покороче, а значит, различия в ТОПах были немного меньше. Но никакой значимой зависимости между частотой запроса и штормом в выдаче по этому запросу, которая действительно кардинально бы меняла ТОП сайтов, обнаружено не было. Отсюда делаем вывод: нестабильность выдачи не зависит от частоты запросов.
Однако ещё на этих графике видно, что значения коэффициента Жаккара доходят до нуля. Это означает, что в некоторых случаях ТОП‑10 выдачи по запросу могут быть полностью различны в один момент времени для разных пользователей. Такая ситуация возможна для запросов любого типа.
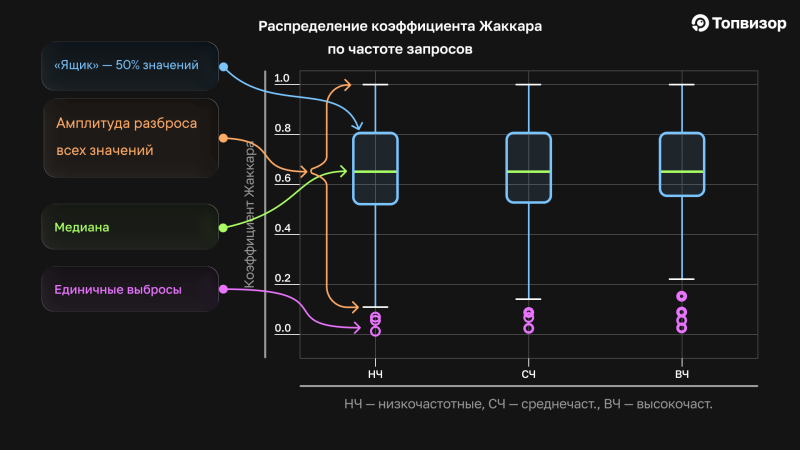
А ещё здесь видно, что разброс коэффициента Жаккара во всех группах почти максимальный — от 0 до 1. 50% всех значений сосредоточены вокруг значения коэффициента на уровне 0,55‑0,8, что означает, что в среднем 8‑9 сайтов в ТОПах совпадают. Но амплитуда разбора очень большая. А это значит, что даже если обращаться к выдаче в одно и то же время, она не отдаёт одинаковые ТОПы. Включая крайние случаи с нулевым значением коэффициента, которые свидетельствуют о полном несовпадении ТОПов между собой. То есть вы два раза обращаетесь к выдаче и получаете абсолютно разные списки сайтов.
Но на графике выше мы анализировали средние значения по всем источникам, Yandex Search API и SERP. Поэтому возникает вопрос: как отличается шторм внутри источников и отличается ли он вообще? Внутри источников — то есть при обращении только к SERP или только к Search API.
Миф 2: API — это отдельная выдача, и позиции там не такие, как в «живом» SERP
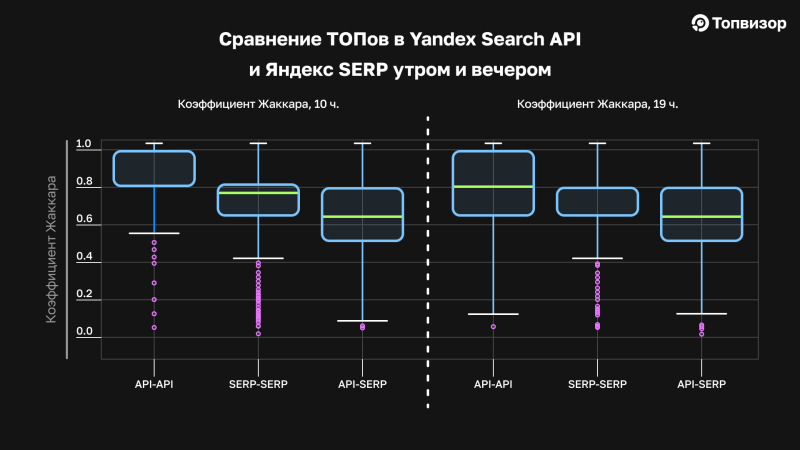
Чтобы развеять миф о том, что API — какая‑то отдельная выдача, которую вообще не видят реальные люди, обратимся к уже знакомому нам ящику с усами. Ниже представлены средние графики по всем проверкам утром и вечером, в 10 и 19 часов. На них выведен коэффициент Жаккара при сравнении ТОПов из Yandex Search API и SERP. Среднее по проверкам утром и вечером. Три оси сравнения — это сравнения множеств: API с API, SERP c SERP и API с SERP.
- API‑API обозначает, что сравнивались ТОПы, полученные в результате запросов, отправленных одновременно в Yandex Search API;
- SERP‑SERP обозначает, что сравнивались ТОПы, полученные только из SERP;
- API‑SERP обозначает, что ТОПы, полученные из Yandex Search API, сравнивались с ТОПами из SERP или «живой» выдачи.
Насколько стабилен Yandex Search API
Если мы посмотрим на «ящик» API‑API в утреннее время и вечернее, то увидим, что разброс значений утром гораздо меньше, чем вечером. Исходя из чего делаем вывод, что позиции в API в утренние часы стабильнее — ТОПы почти идентичны (они близки к коэффициенту 1). Однако единичные выбросы всё равно присутствуют. Это точки, в которых коэффициент Жаккара стремится к нулю, то есть совпадение сайтов — минимальное.
Вечером в данных Yandex Search API график «ящик с усами» смещается вниз — снижаются как медиана, так и нижняя граница ящика, который содержит 50% всех значений. При этом нижний ус опускается, а точки, которые утром считались выбросами, вечером оказываются в пределах усов, то есть становятся частью основного распределения.
Так мы получаем не самый приятный для Топвизора вывод: позиции действительно будут более однородные, с меньшим количеством выпадений, если проверять их утром, как и любят делать сеошники, создавая нам повышенную нагрузку. Молодцы, вы это чувствовали, продолжайте в том же духе 🙂
А как дела в SERP?
В SERP же наоборот. Мы видим стабильное несовпадение в ТОПах, который почти никак не меняет свою силу в течение дня. «Ящик» не смещается, присутствует много выбросов, которые означают, что при двух одновременных запросах к выдаче вы получаете абсолютно разные ТОПы.
Вывод: в «живой» выдаче шторм есть всегда, и он не зависит от времени суток. А «выбросов» в позициях, когда вы можете увидеть абсолютно другой ТОП, намного больше, чем в API.
И, наконец, API vs SERP
И, наконец, сравним API и SERP. На графике видно, что ТОПы всё ещё разные, но не полностью — в ТОПе совпадают 7‑9 сайтов, что соответствует коэффициенту Жаккара — 0,53‑0,81.
Обратимся к ещё одному графику, который покажет, что API и SERP выдача очень схожи.
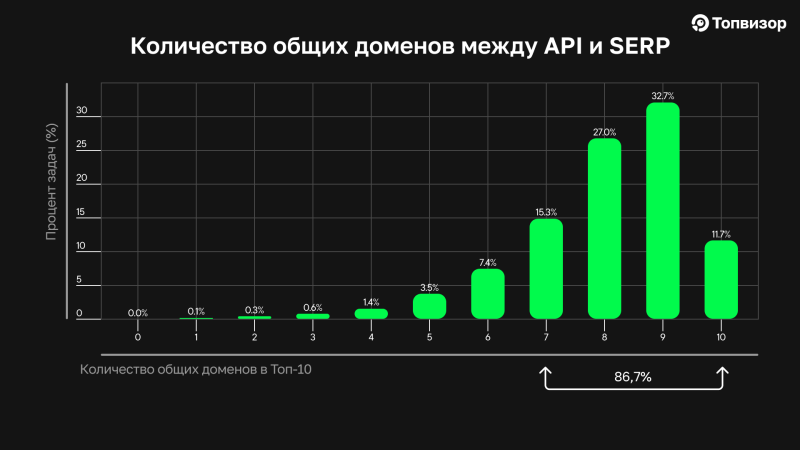
На нём показано процентное соотношение задач, в которых совпадало от 0 до 10 доменов между Yandex Search API и SERP. Как мы видим, самое большое число составляют параллельные запросы, в которых совпадали 7‑8‑9 сайтов. Совпадение не 100%, но, как мы выяснили в сравнении запросов внутри SERP, даже в нём самом оно таким не может быть. В любом случае в самой «живой» выдаче пара сайтов, да будет различаться.
Если взять сессии, где совпадают 7‑10 доменов, что, на мой взгляд, является высоким процентом совпадения, таких задач будет 86,7% от общего числа.
Но графики выше не показывают, насколько сохраняется порядок доменов в ТОПе, только наличие самих доменов. Поэтому проверим, сохраняется ли порядок сайтов в ТОПах.
Миф 3. Порядок сайтов в Yandex Search API разительно отличается от Яндекс SERP
Чтобы разрушить этот миф, используем Коэффициент ранговой корреляции Спирмена. Он оценивает силу и направление монотонной связи между двумя рядами данных. В контексте ТОПов монотонная связь — это порядок сайтов, а ранги — это порядковые номера значений, или позиции. Покажем его расчёт на примере.
Формула:
ρ = 1 — [ (6 * Σd²) / (n * (n² — 1)) ],
где:
-
ρ (ро) — коэффициент корреляции Спирмена.
-
Σd² — сумма квадратов разностей рангов.
-
n — количество наблюдений (в нашем случае 10).
Сравним 2 ряда (ТОПа) сайтов:
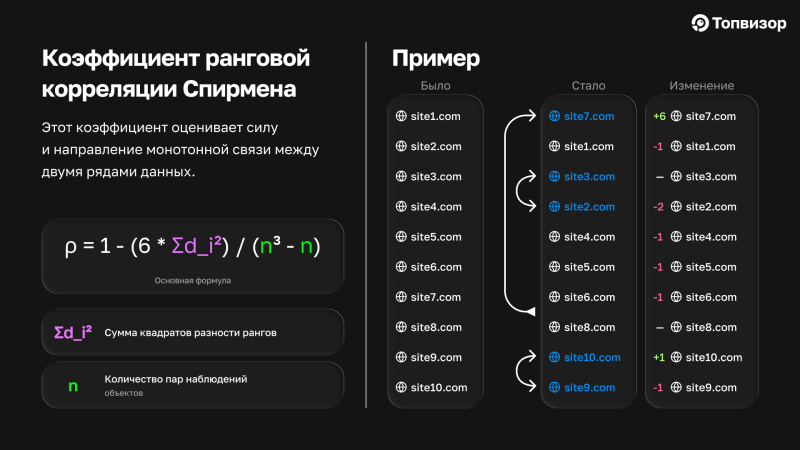
Во втором ряду 7‑й сайт встал на 1‑е место, 2 и 3 поменялись местами и 9‑й с 10‑ым тоже. Если оценивать ранги сайтов, то только сайты 3 и 8 остались на своих местах, но при этом все домены остались такими же, то есть по Жаккару это будет единица.
Почему я поменяла сайты именно так? Исходя из моей практики, это обычная перемешка сайтов, которую я бы не назвала серьезным изменением. То есть один сайт куда‑то «скакнул», пара сайтов поменялись местами, но список доменов в целом остался таким же, каким был изначально.
Чтобы вычислить коэффициент, создадим таблицу, где для каждого сайта пропишем его ранг в первой ранжировке (R1) и его ранг во второй ранжировке (R2).

Потом для каждого сайта вычислим разность между его рангами: d = R1 — R2. Затем возведём каждую разность в квадрат: d².
Потом найдём сумму всех значений в столбце d²:
Используем формулу и получаем, что Коэффициент ранговой корреляции Спирмена равен примерно 0,721.
Выводы, которые можем сделать на основании расчётов, приведённых выше:
-
В нашем случае значение коэффициента находится в диапазоне от 0 до +1, что указывает на положительную связь между двумя ранжировками. Положительная связь — это когда объекты, имеющие высокий ранг в первой последовательности, имеют высокий ранг и во второй. Коэффициент может быть и нулевым, и отрицательным. Тогда между двумя ранжировками существует обратная связь — это когда объекты, имеющие высокий ранг (позицию) в первой последовательности, имеют низкий ранг во второй.
-
Силу связи можно оценить как умеренную (обычно считается, что значение выше 0,7 указывает на сильную связь). При умеренной силе связи оба списка сайтов в целом похожи по своему порядку, но есть и заметные различия.
-
Главное расхождение вносит site7.com, который в первом списке находится в середине (позиция 7), а во втором — на первом месте (ранг 1). Это стало основной причиной того, что коэффициент не приблизился к единице. Остальные сайты в основном сместились на 1‑2 позиции.
А теперь посмотрим, как распределился коэффициент Спирмена во всех задачах, которые мы получили при сравнении Yandex Search API и Яндекс SERP.
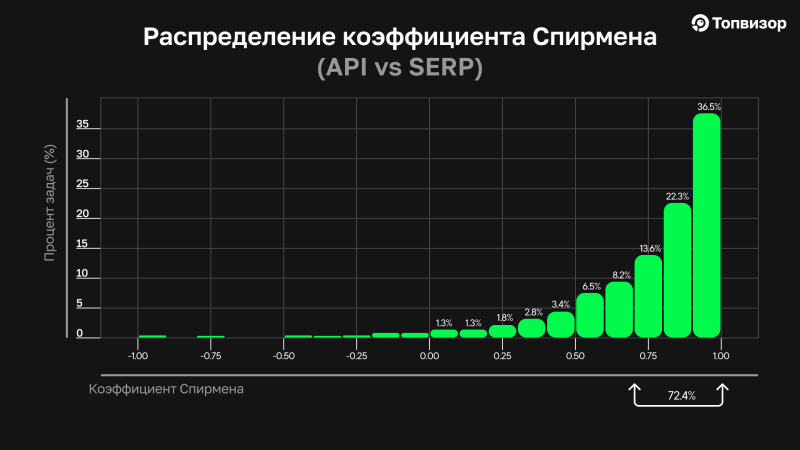
Напомним, мы сравнивали Yandex Search API и «живую» SERP‑выдачу. Как видно на графике, в абсолютном большинстве задач коэффициент Спирмена был выше 0,7. А сессии, которые встречаются чаще всего, имеют коэффициент 1 — то есть ряды (порядок сайтов) одинаковые.
Коэффициент у примера, который я показывала, составил 0,72. То есть в большинстве задач примерно вот такие изменения и были.
Получается, что в большинстве сессий при сравнении API и SERP сохраняется также порядок сайтов, а не только количество совпадающих доменов.
И в финале давайте сравним, насколько ТОПы различаются в API и SERP в зависимости от дня недели по Жаккару и Спирмену. Напомним, Жаккар отвечает за то, насколько в ТОПах одинаковые домены, а Спирман — за то, насколько похож их порядок. Рассмотрим на примере данных, полученных за понедельник и воскресенье. На графиках также есть четверг, но так как он почти полностью совпадает с воскресеньем, я не буду его отдельно комментировать.
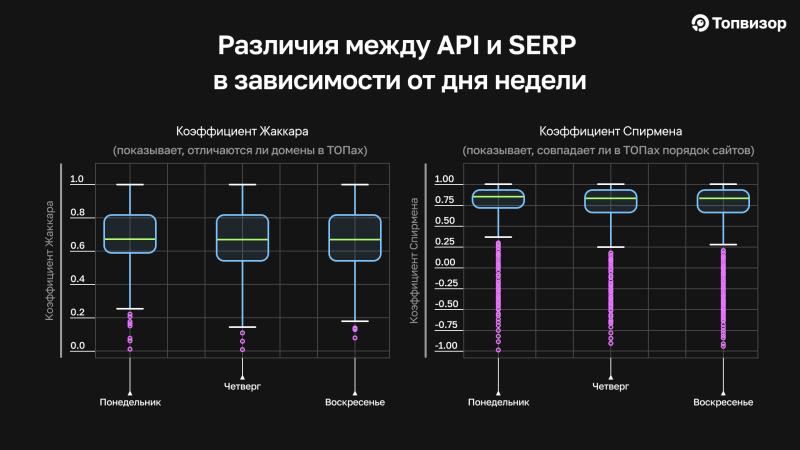
Мы видим и по коэффициенту Жаккара, и по коэффициенту Спирмена, что в понедельник ТОПы в SERP и API чуть больше совпадают, они принимают значения, близкие к 1, а в воскресенье разброс данных немного больше, на что указывают границы графика ящик с усами. Различия совсем небольшие, и, например, если переводить коэффициент Жаккара на домены, то и в понедельник, и в воскресенье ТОПы всё равно совпадают на уровне 8 доменов из 10. Но статистически они есть, и мы не можем о них не сказать.
Значения всё равно во все дни остаются довольно высокими: 7‑8 и даже 9 одинаковых доменов по Жаккару и небольшие изменения в порядке сайтов по Спирмену. Но присутствует много выбросов. То есть среднее — это хорошо, но шанс попасть на какую‑то «отстойную» выдачу, которая и по самим ТОПам, и по порядку сайтов различается на 100%, в том числе у нашего робота, в том числе при нашей ручной проверке, никогда не равен нулю.
А что в итоге?
Давайте зафиналим этот текст ещё одним графиком. Последним, честное слово!
Ниже вы видите 2 графика по запросу «курс доллара», сверху API, снизу SERP. Каждый цвет — это определённый домен.

Перед нами настоящий калейдоскоп. Помните, мы говорили, что API более стабильный. В API сайт на 1 месте реально не двигается. Это одна из проверок, которые мы делали, в каких‑то других он может и сместился, но в этом пуле — он реально неподвижен. А в SERP в каких‑то единичных сессиях он умудряется двигаться.
Так какой же ответ на главный вопрос, кто же врёт? Топвизор, Яндекс, АПИ, сеошники? Ответ такой — а никто! Обвинять кого‑то в том, что он врёт, намного проще, чем разобраться, как всё работает на самом деле. И наш анализ показывает, что выдача нестабильна сама по себе, и это можно исследовать дальше, чтобы вырабатывать оптимальную стратегию для продвижения и пояснять результаты продвижения своим клиентам.

Выводы исследования в двух словах
-
Нестабильность выдачи не зависит от частоты запросов.
-
«Живая» SERP‑выдача не отдаёт одинаковые ТОПы даже в один и тот же момент времени. В среднем совпадают 8 сайтов из 10.
-
В Yandex Search API, как и в SERP, в среднем 8‑9 из 10 сайтов совпадают.
-
В Yandex Search API утром результаты будут чуть более стабильными, чем вечером. Поэтому проверку в Топвизоре утром будет штормить чуть меньше.
-
Амплитуда разброса в ТОПах — максимальная, вплоть до ситуации, когда в соседних проверках в ТОПе другие сайты.
-
API‑ и SERP‑выдача совпадают на 7‑9 сайтов из 10 в любое время суток и в любой день недели, а значит нет отдельной API‑выдачи или «ботовыдачи». API вполне релевантна «живой» выдаче.
-
При сравнении API и SERP сохраняется также порядок сайтов.
-
В понедельник ТОПы в API и SERP чуть больше совпадают друг с другом и по количеству общих доменов, и по порядку сайтов.