
Почему дубли страниц — это плохо
Дубли негативно сказываются на SEO‑продвижении сайта — это дополнительная трата ресурсов как специалиста, так и поисковой системы:
-
Ухудшается индексация сайта.
При наличии дублирующихся страниц на сайте поисковые роботы могут индексировать их вместо оригинальных, и краулинговый бюджет тратится впустую. Кроме этого, одинаковые страницы на сайте просто затрудняют работу поискового робота — ведь он посещает каждую из них отдельно.
-
Снижаются позиции по ключевым запросам.
Индексация дублей вместо нужных страниц сайта приводит к снижению позиций в поисковой выдаче.
-
Страницы начинают конкурировать между собой.
Дубли могут как объединяться в группы, так и участвовать в поиске как разные документы; это может привести к каннибализации. Она усложняет работу поисковых систем и снижает шанс оригинальной страницы на индексирование.
Что такое каннибализация ключевых слов в SEO и как её избежать
-
Теряется пoлeзный внyтpeнний ccылoчный вec.
Это влияет на авторитетность сайта и на дальнейшее его цитирование.
-
Сайт может попасть пoд фильтры ПС.
Переходы из поисковых систем на сайт прекратятся, если Яндeкс применит фильтр AГC, а Google — Panda.
-
Усложняется сбор аналитических данных, затрудняется интерпретация веб‑аналитики.
По поисковому запросу отражается одна страница; попадание дублей в запрос усложняет сбор аналитических данных и их интерпретацию.
Откуда берутся дубли страниц
Основные причины:
1. Ошибка сотрудника
Случайно созданные дублирующиеся страницы поможет избежать поможет контент‑план и регулярная ревизия сайта.
2. Некорректно заданные параметры ссылок
Дубли возникают при неправильной передаче технической информации через ссылки: например, при фильтрации и сортировке товаров, использовании фильтров отображения контента на странице и UTM‑меток.
Виды дублей страниц
Дубли страниц сайта бывают трёх видов: полные, частичные и смысловые.
-
Полные дубли — когда страницы содержат абсолютно одинаковый контент.
-
Частичные дубли — страницы имеют общую семантику и задачи, содержат похожий контент, но не являются полными дублями.
-
Смысловые дубли — несколько разделов страниц имеют одинаковый смысл, переданный разными словами.
Как найти дубли страниц
Через парсинг
Парсинг — это автоматический сбор и анализ данных с веб‑ресурса при помощи программ и сервисов.
Алгоритм копирует весь контент, который есть на странице, и разбивает его на данные: заголовки, картинки и т. д. Таким образом, можно отследить открытую информацию: например, товарные позиции и цены; метаданные; редиректы и страницы, выдающие ошибку.
Существует огромное количество парсеров: платные и бесплатные, облачные и десктопные.
Программа для скачивания на Windows, macOS и Linux.
Стоимость: 199 евро в год. Бесплатная версия программы может парсить до 500 страниц c 90%‑ным совпадением. Можно настроить меньший процент.
Как пользоваться:
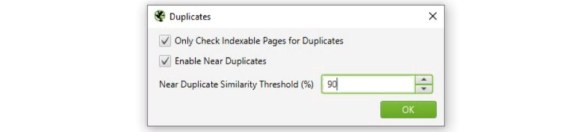
- Настройте определение дубликатов с точностью до 90 % или ниже. В зависимости от задачи настройте выявление точных дубликатов и проверку только индексируемых страниц.
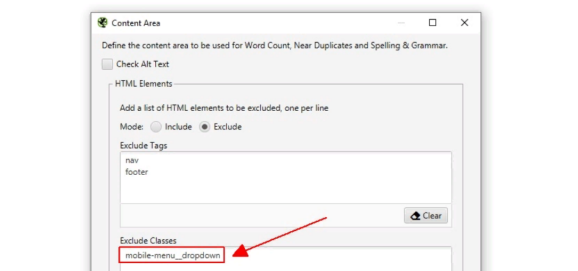
- Настройте проверку основного контента через «исключение классов» — mobile‑menu__dropdown.
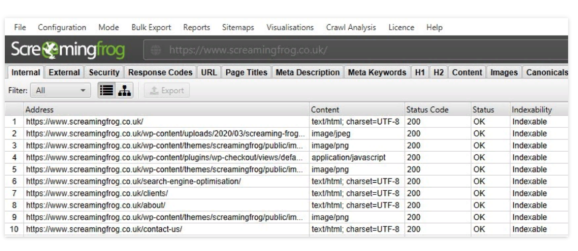
- Вставьте ссылку и нажмите Enter.
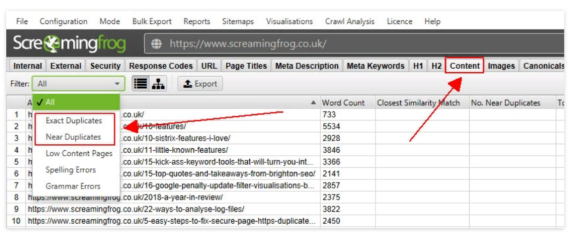
- Просмотреть дубликаты можно во вкладке «Контент».
Бесплатный парсер для ПК с Windows.
Программа создана для поиска битых ссылок, но помогает выявить и дубли страниц. SEO‑специалист Артём Болотов показал, как использовать парсер Xenu’s Link Sleuth для проверки уникальности страниц, в кейсе «Как удалить 12 тысяч дублей и попасть в ТОП Яндекса за три месяца».
Откройте Анализ сайта и перейдите в раздел «Страницы» на вкладку «Контент». По скроллу вправо можно найти дубли title и description:
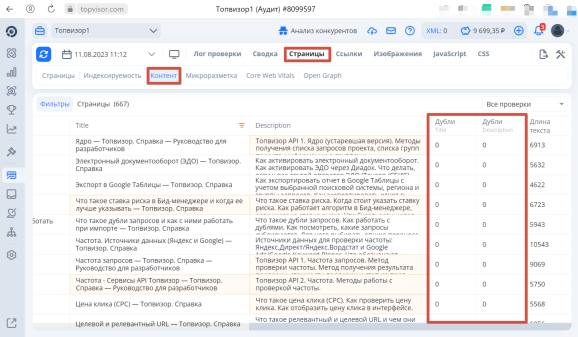
Как сделать качественный SEO‑аудит сайта самостоятельно: полное руководство
Как выбрать парсер
-
Поставьте чёткую задачу: это может быть мониторинг цен, сбор данных для каталога, SEO‑анализ или другая задача.
-
Определите, какой объём данных нужно исследовать, получить и в каком формате.
-
Выберите частоту получения информации.
Исходя из этих пунктов и бюджета, вы сможете выбрать наиболее подходящий сервис.
Артём Бирюков, автор телеграм‑канала «О SEO по делу — блог о SEO‑оптимизации»:
«Чаще всего для поиска дублей я делаю парсинг через Screaming Frog и работаю с данными панелей вебмастера. Парсинг даёт информацию по всем страницам сайта, которые перелинкованы между собой. Работа с вебмастерами позволяет получить данные напрямую из поиска, в том числе по страницам, которые не имеют ссылок с сайта. На крупных сайтах подключаю анализ логов сервера».
С помощью операторов Google и Яндекса
Дубли можно найти вручную с использованием операторов Google и Яндекса. Например, intext показывает страницы, которые содержат указанное слово в тексте, а allintext находит страницы, содержащие все указанные слова.
Полный список поисковых операторов Google
В Вебмастере и GSC
Яндекс Вебмастер
-
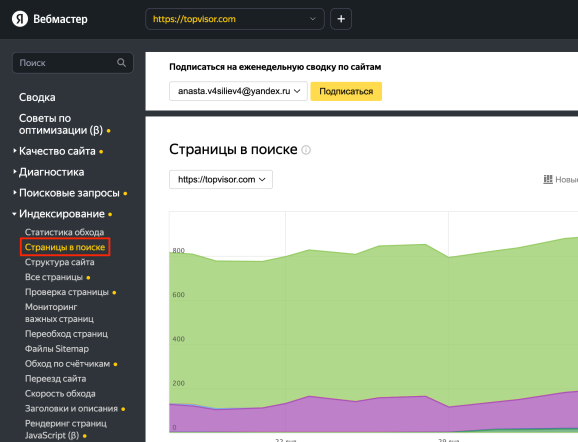
Перейдите на вкладку «Индексирование» в раздел «Страницы в поиске».
-
По скроллу вниз вы увидите список URL; выберите «Исключённые страницы». Отфильтруйте их по параметру «Дубль».
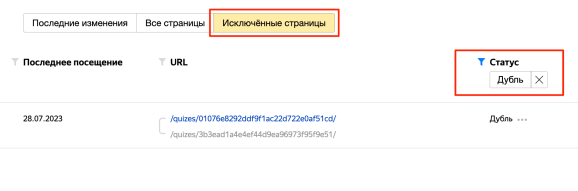
При выгрузке результатов проверки в файлы форматов XSL или CSV дубли будут обозначены как «DUPLICATE».
🔥 Всё, что нужно знать о Яндекс Вебмастере и Google Search Console, ищите в наших гайдах по сервисам.
Google Search Console
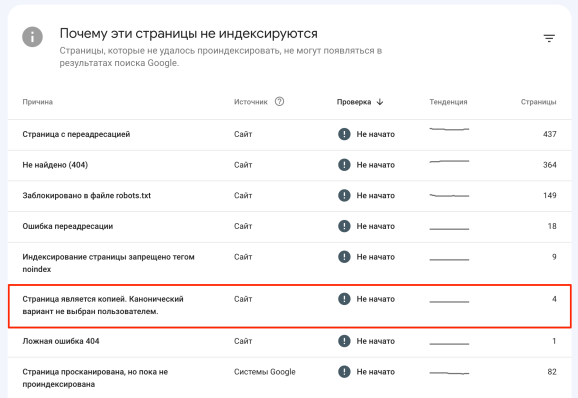
- Нажмите на вкладку «Индексирование» и выберите «Страницы».
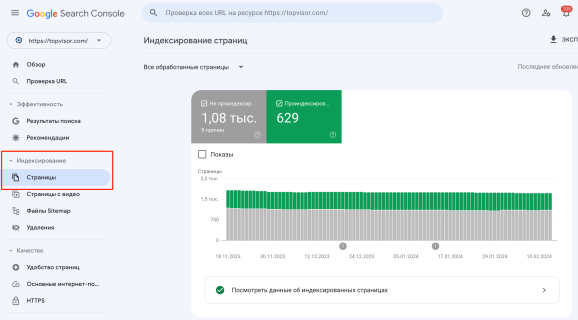
- По скроллу вниз расположен перечень ошибок, мешающих индексированию, в числе которых на дубли будет указывать строка «Страница является копией. Канонический вариант не выбран пользователем».
Как удалить дубли страниц на сайте
Физическое удаление
Самый простой способ — удалить вручную в административной панели. Прежде чем действовать, нужно разобраться, каким образом дубль появился и не ссылаются ли на него другие источники. Так удаление не повлияет на продвижение или повлияет минимально.
Настройка 301 редиректа
301 редирект позволяет настроить перенаправление страниц на один адрес, например: «http://www.topvisor.ru/catalog/catalog‑name/» вместо «http://topvisor.ru/catalog/catalog‑name/index.php». Это можно сделать в корневом каталоге веб‑сервера в файле htaccess.
Переадресация с http на https
RewriteCond %{HTTP:X‑Forwarded‑Protocol} !=https
RewriteRule .* https://%{SERVER_NAME}%{REQUEST_URI} [R=301,L]
Перенаправление со страниц без www на www
Если нужно, чтобы сайт открывался только с www, пропишите код:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^correct‑domain.ru
RewriteRule (.*) http://www.correct‑domain.ru/$1 [R=301,L]
Если нужно сделать наоборот, то код будет выглядеть так:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.correct‑domain.ru
RewriteRule ^(.*)$ http://correct‑domain.ru/$1 [R=301,L]
- correct‑domain.ru — адрес вашего домена.
🔥 Об этом мы уже рассказывали — читайте, как правильно переходить с http на https и как настроить редирект с www на адрес без www.
Перенаправление со страниц без слэша на конце, на «/»
Убираем слэш в конце:
RewriteCond %{REQUEST_FILENAME} !‑d
RewriteCond %{REQUEST_URI} ^(.+)/$
RewriteRule ^(.+)/$ http://www.site.ru/$1 [R=301,L]
Добавляем слэш в конце:
RewriteCond %{REQUEST_FILENAME} !‑f
RewriteCond %{REQUEST_URI} !\..{1,10}$
RewriteCond %{REQUEST_URI} !(.*)/$
RewriteRule ^(.*)$ http://www.site.ru/$1/ [L,R=301]
Ставить завершающий слеш в URL или нет: как лучше для SEO
Перенаправление со старой страницы на новую
Redirect 301 %old_url% %new_url%
-
%old_url% — старый адрес страницы без домена.
-
%new_url% — новый адрес страницы с указанием домена и протокола.
Смена домена
RewriteEngine on
RewriteCond %{HTTP_HOST} !^www\.correct‑domain\.ru(:80)?$
RewriteRule (.*) http://www.correct‑domain.ru/$1 [R=301,L]
RewriteEngine on
RewriteCond %{HTTP_HOST} !^www\.correct‑domain\.ru(:443)?$
RewriteRule (.*) http://www.correct‑domain.ru/$1 [R=301,L]
Выбор канонической страницы
Удалить дубли на сайте можно при помощи атрибута canonical. Его помещают в шапку между открывающим тегом <head> и закрывающим </head>:
<link rel=”canonical” href=”адрес основной страницы” />
Canonical: что это за атрибут и как прописать канонический адрес страницы
Запрет индексации через robots.txt
В файле robots.txt с использованием директивы Disallow можно запретить индексирование отдельных дублей:
User‑agent: * Disallow: /dublictate.html Host: topvisor.com
Артём Бирюков, автор телеграм‑канала «О SEO по делу — блог о SEO‑оптимизации»:
«Начинающим SEO‑специалистам я бы рекомендовал для удаления дублей удалить и настроить 301 редирект. При настройке редиректа замените внутренние ссылки актуальными на целевую страницу. Также мы можем закрыть от индексации в robots.txt директивой disallow, либо указать каноническую страницу, а для незначащих параметров пользоваться clean‑param.
В любом случае выбирать метод удаления нужно, исходя из источника и типа дублирования».
Что запомнить
Наличие дублирующихся страниц негативно сказывается на SEO‑продвижении сайта: они мешают поисковой системе индексировать необходимый вам контент.
Найти дубли на сайте помогут:
-
Screaming Frog — парсит до 500 страниц бесплатно с совпадением до 90 %.
-
Парсер Xenu’s Link Sleuth — разработан для поиска битых ссылок, но его можно использовать и при поиске дублей.
-
Анализ сайта в Топвизоре — ищет дубли Title и Description.
- Панели вебмастеров — Яндекс Вебмастер и Google Search Console;
- Поисковые операторы Google и Яндекса для работы вручную.
Найденные дубли нужно удалить одним из доступных способов:
- Настройка 301 редиректа;
- Выбор канонической страницы;
- Запрет индексации через robots.txt;
- Удаление дублей физически в административной панели. Прежде чем это сделать, нужно разобраться, проиндексирована ли страница, как она влияет на трафик и ссылаются ли на неё другие источники.
Ещё по теме
Как бороться с дублированием контента с помощью канонизации