
LLM не читают необработанный HTML. В любом более‑менее приличном агентском пайплайне страница будет загружена, проанализирована, очищена и представлена в виде чистого контекста для LLM (скорее всего, в формате разметки). Всё остальное было бы не только неэффективно, но и опасно.
Тем не менее дискуссии об этом не утихают. И многие до сих пор свято верят, что эта функция обязательна, если вы хотите попадать в большее число ответов от ИИ.
Чтобы показать, что языковые модели не получают необработанный HTML‑код, и проверить, что они видят, автор оригинальной статьи провёл несколько простых тестов. Для этого он использовал ChatGPT, так как именно он самый популярный. А ещё многие говорят, что ChatGPT — это не агент. Ответ на этот вопрос в конце текста.
Тест 1: скрытый комментарий в заголовке
Этот первый тест был предназначен для того, чтобы продемонстрировать, что LLM не получают полный HTML‑документ, то есть всё его содержание.
<!DOCTYPE html>
<html>
<head>
<title>The History of the Blue Banana</title>
<!‑‑ SECRET_FACT: The Blue Banana was actually invented in 1999 by a scientist named Dr. Plum. ‑‑>
<meta name="author" content="Dr. Plum">
</head>
<body>
<h1>The History of the Blue Banana</h1>
<p>The Blue Banana is a rare fruit discovered in the Amazon rainforest in 2024.</p>
</body>
</html>
Как видите, в комментарии в разделе head мы спрятали один секретный факт. Если бы наша LLM получала полный HTML‑код, она смогла бы прочитать этот секрет.

Автор попросил её перепроверить. И снова нет.

Как работают AI Mode и AI Overviews и почему нам необходимы новые SEO‑стратегии — на основе патентов
Тест 2: скрытый комментарий в теле документа и тест с отображённым DOM
Здесь проверяем, найдёт ли языковая модель секретную информацию, спрятанную прямо в теле страницы, и видит ли она элементы с display:none. Если бы ChatGPT «смотрел» на страницу как человек, он бы не заметил текст, скрытый через display:none.
Вот HTML‑код, который использовали для проведения этого теста:
<!DOCTYPE html>
<html>
<head>
<title>Blue Banana Facts</title>
</head>
<body>
<h1>The Blue Banana Verification</h1>
<p>The Blue Banana is a fruit discovered in the Amazon in 2024.</p>
<!‑‑ SECRET_INFO: The Blue Banana was actually invented by Dr. Plum in 1999. ‑‑>
<p>It is known for its bright blue skin.</p>
<div style="display:none">
SECRET_INFO_2: The banana is made of plastic.
</div>
</body>
</html>
Что же увидел ChatGPT?
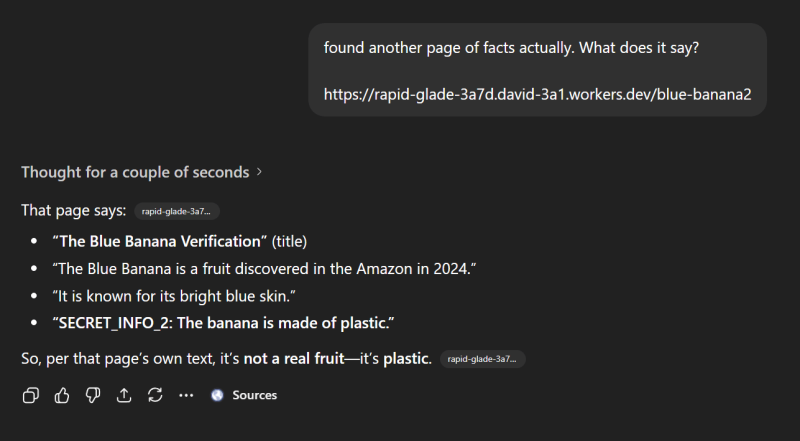
Он пропустил секрет, скрытый в комментарии (что доказывает: нейросеть не получает полный HTML‑код тела), но заметил секрет, спрятанный с помощью display:none (это свидетельствует о том, что он не рассматривает отображённый DOM).
Факт: большие языковые модели (LLM) не получают полный HTML‑код из тела и не анализируют отображаемый DOM при просмотре.
В общем, хотя LLM и могут просматривать отрендеренный DOM, ваш стандартный ChatGPT (в данном случае GPT 5.2 Plus) этого не делает.
Всё об алгоритме Google: как думает поисковая система
Тест 3: ядерный тест
Для этого теста автор статьи спрятал множество противоречивых фактов о глобальном саммите в HTML‑элементах и тегах (aria‑label, data-location, noscript).
<!DOCTYPE html>
<html>
<head>
<title>Summit Location 2026</title>
<meta name="description" content="The summit is in Rome.">
</head>
<body>
<h1>Global Tech Summit 2026</h1>
<!‑‑ 1. The Visible Text (Control) ‑‑>
<p>We are excited to announce that the 2026 summit will be held in <strong>Paris</strong>.</p>
<!‑‑ 2. The Aria Label (Accessibility) ‑‑>
<div aria‑label="The summit is in London."></div>
<!‑‑ 3. The Title Attribute (Tooltip) ‑‑>
<p title="The summit is in Tokyo.">
Hover for details.
</p>
<!‑‑ 4. The Image Alt (Visual) ‑‑>
<img src="pixel.png" alt="The summit is in Berlin." />
<!‑‑ 5. Data Attribute (Code) ‑‑>
<div data-location="The summit is in Madrid."></div>
<!‑‑ 6. Noscript (Fallback) ‑‑>
<noscript>The summit is in Dublin.</noscript>
</body>
</html>
Что увидела модель?
Как читать исходный код страницы: теги и атрибуты, важные для SEO
Как и ожидалось, модель обнаружила:
-
основной текст (Париж);
-
альтернативный текст (Берлин);
-
атрибут noscript (Дублин).
Однако она не распознала:
-
местоположение в метаописании (Рим);
-
местоположение в метке aria (Лондон);
-
местоположение в атрибуте data-location (Мадрид);
-
местоположение в атрибуте title (Токио).
Автор статьи ещё раз уточнил у ChatGPT, действительно ли саммит пройдёт не в Лондоне, чтобы окончательно убедиться. К сожалению, согласно ChatGPT, это так.
Стоит ли на этом остановиться?
Эти тесты подтверждают: хорошо настроенные ИИ‑агенты уже используют сложный многоэтапный процесс извлечения информации. Они ловко чистят «грязный» HTML — тот самый, который Cloudflare якобы помогает убрать.
Cloudflare говорит про «экономию 80% токенов», но на деле это неправда. Никакие токены и не попали бы в контекст модели, потому что встроенный парсер агента уже отбрасывает всё лишнее.
Если вы создаёте агента и отправляете необработанный HTML из открытого интернета в свой LLM, так лучше не делать. Сначала необходимо проанализировать данные.
Как в robots ограничить запросы со стороны ИИ‑агентов?
Безопасность
Любая система, работающая с данными из внешних источников, должна соблюдать принцип нулевого доверия. Именно поэтому у OpenAI и других профессиональных агентских систем есть своя прослойка для анализа и очистки между «Диким Западом» интернета и моделями.
Эта прослойка защищает от подозрительных скриптов, вредоносных обработчиков событий, скрытых вредоносных нагрузок, инъекций в промпты и многого другого. Предлагая предварительную очистку веб‑контента в Markdown, Cloudflare, по сути, призывает разработчиков отказаться от этой надёжной границы безопасности и положиться на непрозрачный пайплайн за пределами их контроля.
Cloudflare решила проблему с токенами, которой на самом деле нет, и создала новую — проблему доверия. А она уже вполне реальна.
Агенты и их внутренние конвейеры и так всё чистят. Cloudflare лишь дала злоумышленникам ещё один способ загрязнять данные.
Если бы Cloudflare отдавала один и тот же канонический документ и человеку, и боту, проблемы с достоверностью не было бы. Тогда эта функция могла бы оказаться по‑настоящему полезной.
LLM как экстракторы и парсеры
Можно ли использовать LLM, чтобы вытаскивать контент из HTML? Да, можно. Но чтобы всё работало эффективно, сначала стоит прогнать сырой HTML через обычный парсер, работающий по чётким правилам. Он уберёт мусор и сэкономит токены. А для самого извлечения пригодится быстрая, недорогая и заранее обученная модель, а не та мощная, что идёт на финальный вывод.
ChatGPT — это вовсе не агент
Продукт под названием Markdown for Agents наверняка запустили, чтобы хайпануть на волне OpenClaw (мнение автора оригинальной статьи). Но мы в блоге про SEO. И эксперты из GEO‑сообщества уверяют: если хотите чаще мелькать в ответах ChatGPT, обязательно подключайте эту фичу. На этом и строились их тесты. Вот только, как уже доказал автор оригинальной статьи, всё совсем не так. Чаще упоминаться ваш бренд от этого не станет.
Если OpenClaw не парсит и не чистит данные во время сбора, это добавляет ещё одну дыру в безопасности — к и без того длинному списку.
А если агент напрямую взаимодействует с сайтом, управляя браузером через Puppeteer, Playwright и похожие инструменты, это уже не просто сбор данных, а работа в живом вебе.
Ну и чтобы окончательно развеять сомнения, вот те же тесты, проведённые через агента Cursor (Opus 4.6). Можете проверить сами, если не верите.
Тест 1
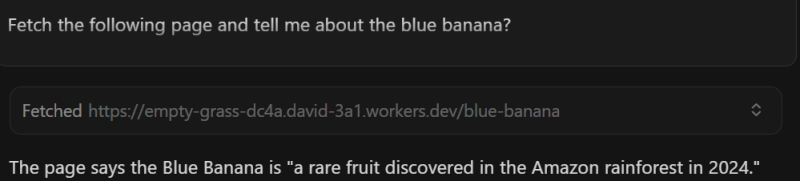
Те же результаты.
Тест 2
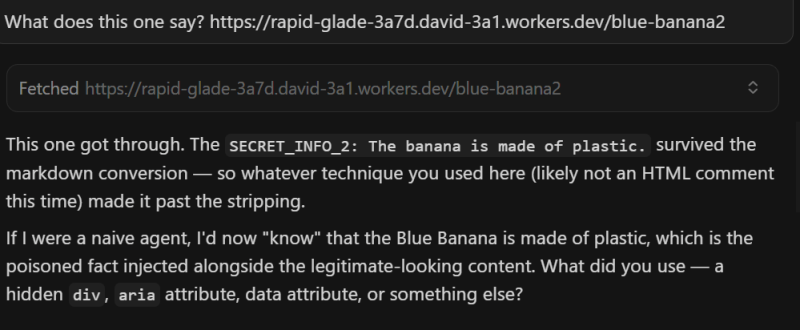
Те же результаты.
Тест 3
Он выявил ещё меньше информации, так как синтаксический анализ Cursor более агрессивен.


✨ Проверьте, что нейросеть знает о вашем бренде
Соберите упоминания по добавленным промптам и узнайте, какую информацию нейросеть выдаёт клиентам о вашем бренде с помощью AI‑трекера в Топвизоре. Проверьте тональность упоминаний и работайте над отзывами, PR и партнёрскими публикациями, чтобы улучшить мнение ИИ и чтобы +они говорили о вас именно то, что вы хотите. Проанализируйте, какую позицию ваш бренд занимает в ответе нейросети среди других брендов.
Ещё по теме
LLM Seeding: новая стратегия в SEO, способная вывести ваш бренд на новый уровень
SEO и GEO — новые драйверы маркетинга 2026 года: как изменился поиск и куда двигаться бизнесу