
В SEO‑сообществе очень мало информации о том, как работают AI Mode и AI Overviews: есть статьи от самого Google, общая информация, и всё. Майкл Кинг провёл масштабное исследование вопроса и поделился шестью патентами, которые проливают свет на работу этих сервисов. Мы перевели и адаптировали исследование для русскоязычной аудитории.
Будущее поиска за вероятностями
Основное различие между классическим поиском информации (10 синих ссылок) и генеративным поиском информации в интернете (диалоговый поиск) заключается в том, что первый был детерминированным, а второй — вероятностным. Проще говоря, старая версия Google отображала контент так же, как его выкладывали на сайт издатели. А в новой версии Google всё по‑другому: сейчас есть много вариаций того, как контент должен рассматриваться, объединяться и отображаться.

В классическом поиске любой контент подвергается анализу и обработке. Однако в выдаче он отображается в том виде, в каком его предоставили, без дополнительной интерпретации со стороны Google.
Можно было влиять на свой рейтинг и эффективность, регулируя несколько хорошо известных факторов, таких как характеристики контента, архитектуру сайта, ссылки и пользовательские факторы.

В контексте генеративного поиска вы по‑прежнему создаёте свой контент, систему, сайт и ссылки для доступа и анализа. Однако существует ряд сложных и непредсказуемых этапов обработки, которые определяют, сможет ли ваш контент стать частью окончательного ответа. Эти этапы также учитывают информацию о взаимодействиях пользователей.
Таким образом, вы можете следовать всем общепринятым практикам SEO, но не пройти через все этапы обработки. ИИ может быть непоследовательным, и один и тот же контент может дважды пройти через одну и ту же цепочку обработки — и дать разные результаты.
AI Overviews от Google — год. Как изменился поиск за это время
Как работают режим ИИ и краткие пересказы от ИИ: разбор патентов
И режим ИИ, и краткие пересказы от ИИ эффективно функционируют благодаря одним и тем же механизмам. Давайте рассмотрим ключевые патенты, которые раскрывают суть их работы. По ссылкам — сами патенты (на английском языке).
-
Поиск с помощью сохраняемого чата. Базовая системная архитектура, на которой работает режим ИИ.
-
Генерируемые ответы для результатов поиска. Базовая системная архитектура, на которой работают краткие пересказы от ИИ.
-
Метод ранжирования текста с помощью парного ранжирования. Метод сравнения фрагментов с помощью рассуждений, основанных на LLM.
-
Модели встраивания пользовательских данных для персонализации последовательной обработки. Способ создания настраиваемых представлений о поведении пользователей для персонализации на основе рассуждений.
-
Системы и методы генерации на основе запросов для диверсифицированного поиска. Метод позволяет обеспечивать более широкий и гибкий поиск.
-
Точная настройка моделей машинного обучения с помощью промежуточных рассуждений. Общее объяснение работы рассуждения в LLM от Google.
Всё об алгоритме Google: как думает поисковая система
Как работает AI Mode
Режим ИИ работает следующим образом: сначала он анализирует и создаёт контекст, в котором находится пользователь, что будет влиять на все последующие задачи. Этот контекст в сочетании с запросом используется для генерации ряда синтетических запросов.
Фрагменты извлекаются из документов, которые ранжируются в соответствии с набором запросов. Затем выполняется классификация запроса, которая определяет, какая из моделей LLM (больших языковых моделей) будет использоваться. Эти отрывки проходят через серию логических цепочек, и те, которые проходят, синтезируются в ответ.
Этот ответ уточняется на основе персональных данных пользователя. Извлекаются отрывки, и в конце концов ответ отображается для пользователя.
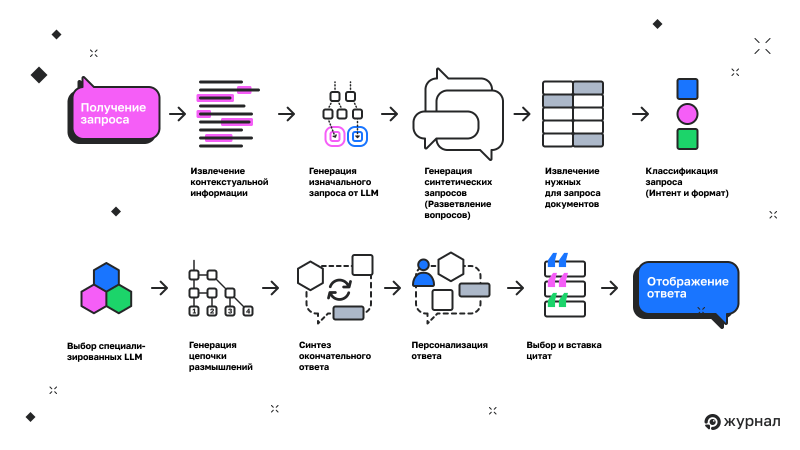
В патенте «Поиск с сохраняемым чатом» рассматриваются различные варианты реализации этого процесса. Давайте подробнее остановимся на одной из схем, чтобы понять логику работы системы.
Архитектура режима ИИ от Google, представленная на рисунке, представляет собой многоступенчатую систему, основанную на рассуждениях. Она проходит путь от интерпретации запроса к синтетическому расширению и, наконец, к генерации ответа на естественном языке.
Каждый этап этого процесса играет важную роль в обеспечении видимости и объясняет, почему традиционные тактики SEO не всегда эффективны в этой среде.
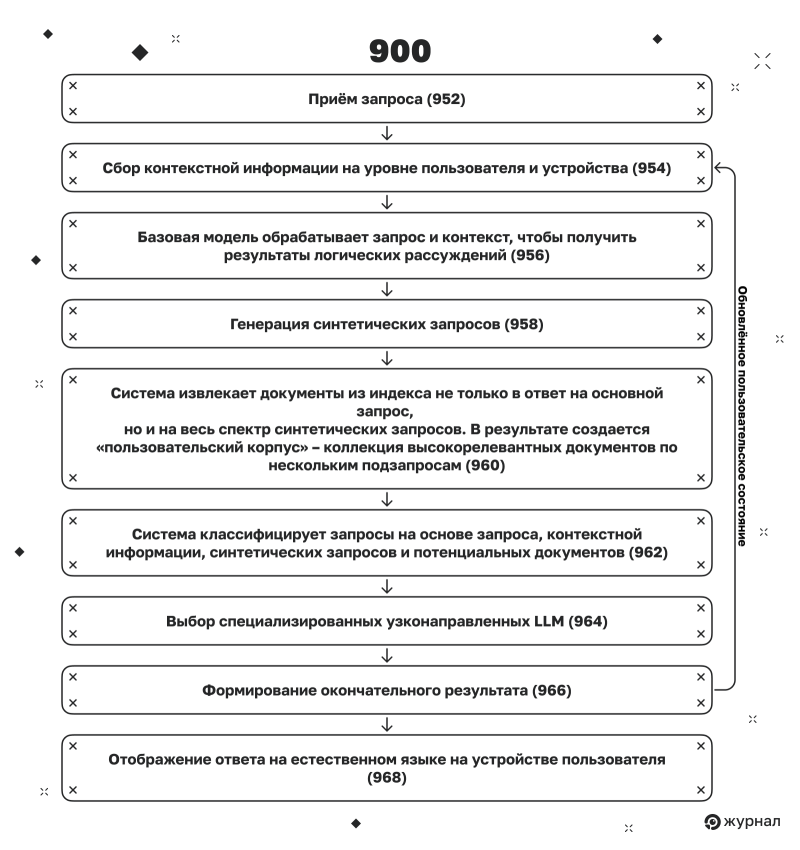
Шаг 1. Приём запроса (952)
В момент ввода запроса система принимает его. Однако, в отличие от традиционных поисковых систем, этот запрос не рассматривается как самостоятельная единица. Он служит лишь отправной точкой для более масштабного процесса синтеза информации, а не как чёткий запрос на поиск.
Шаг 2. Сбор контекстной информации (954)
Система обращается к контекстной информации, собранной на уровне пользователя и устройства. Она учитывает предыдущие запросы в рамках текущей сессии, местоположение, поведение, связанное с учётной записью (Gmail, Карты), и данные из памяти устройства. Это позволяет системе глубже понять запрос, учитывая его временные и поведенческие аспекты.
Шаг 3. Формирование первоначального вывода от LLM (956)
Базовая модель (например, Gemini 2.5 Pro) обрабатывает запрос и контекст, чтобы получить результаты логических рассуждений. Эти результаты могут включать в себя выявленный интент, ответ на вопрос и классификацию. Этот шаг способствует тому, что система начинает понимать, чего именно хочет пользователь.
Шаг 4. Генерация синтетических запросов (958)
Результаты, полученные с помощью LLM, используются для создания нескольких синтетических запросов, которые представляют собой различные переформулировки исходного запроса. Эти запросы могут включать связанные, имплицитные, сравнительные, недавние или исторически связанные термины, создавая некое поисковое созвездие. Это процесс разветвления запросов, который мы подробно обсудим позже.
Шаг 5. Поиск документов, отвечающих запросу (960)
Система извлекает документы из индекса в ответ не только на основной запрос, но и на весь спектр синтетических запросов. В результате создаётся «пользовательский корпус» — коллекция высокорелевантных документов по нескольким подзапросам.
Шаг 6. Классификация запроса на основе данных (962)
Система классифицирует запросы на основе запроса, контекстной информации, синтетических запросов и потенциальных документов. Это позволяет определить, какой тип ответа требуется: объяснительный, сравнительный, транзакционный и так далее.
Шаг 7. Выбор специализированных узконаправленных LLM (964)
На основе классификации система обращается к ряду специализированных моделей, например к тем, что созданы для резюмирования, структурированного извлечения, перевода или поддержки принятия решений. Каждая из этих моделей вносит свой вклад в преобразование необработанных документов в полезную синтетическую информацию.
Шаг 8. Формирование окончательного результата (966)
Эти специальные модели генерируют окончательный ответ на естественном языке, потенциально объединяя несколько отрывков из разных источников и форматов (текст, видео, аудио).
Действительно ли пользователи более вовлечены в контент, когда переходят с ИИ‑выдачи на сайт?
Шаг 9. Отображение ответа на устройстве пользователя (968)
Синтезированный ответ на естественном языке отправляется пользователю, часто с цитатами или интерактивными элементами, извлечёнными из найденного корпуса. Если ваш контент цитируется, это может привести к увеличению трафика. Однако часто ответ напрямую удовлетворяет пользователя, уменьшая необходимость перехода по ссылке.
Режим ИИ представляет собой кардинальную смену подхода к оценке контента. В отличие от традиционных методов SEO, где рейтинг основан на одном критерии, в этом режиме он формируется на основе множества факторов.
Чтобы понять, как сделать наш контент подходящим для цитирования, нам как сообществу предстоит провести множество экспериментов. Однако эти усилия могут не привести к значительному увеличению трафика.
Поведение пользователей в режиме ИИ имеет совсем другие паттерны, поэтому нам необходимо проводить новые исследования и анализы.
Как работают AI Overviews
Хотя о кратких пересказах от ИИ уже говорилось ранее, сейчас самое время вернуться к этой теме в свете новых знаний, полученных в результате изучения режима ИИ. Например, техника разветвления запросов не рассматривалась в предыдущих исследованиях кратких пересказов, где проводилось сравнение классического перекрытия рейтингов. Матрица запросов, используемая для генерации этих ответов, поможет нам понять, как действовать дальше.
В патенте «Генерируемые ответы для результатов поиска» описано несколько методов, но важно поговорить о двух различных подходах к кратким пересказам от ИИ. В первом подходе Gemini сначала генерирует ответ, а затем ищет подтверждение. Во втором подходе он извлекает контент и только потом создаёт ответ.
Вариант с разветвлением запросов
В этой версии процесса Google строит ответ, опираясь на более широкий спектр поисковых запросов, связанных как семантически, так и поведенчески. Вместо того чтобы просто находить результаты по явному запросу пользователя, система активно извлекает документы, связанные с похожими, недавними и подразумеваемыми запросами. Для этого используется более упрощённая версия разветвления запросов, чем та, что применяется в режиме ИИ.
Из этого обширного массива информации генерируется ответ, которое затем проходит проверку перед показом пользователю. Этот процесс представляет собой комбинацию расширенного поиска и синтеза на основе логических рассуждений. Давайте рассмотрим каждый шаг более подробно и выясним, какое значение эти шаги имеют для SEO.
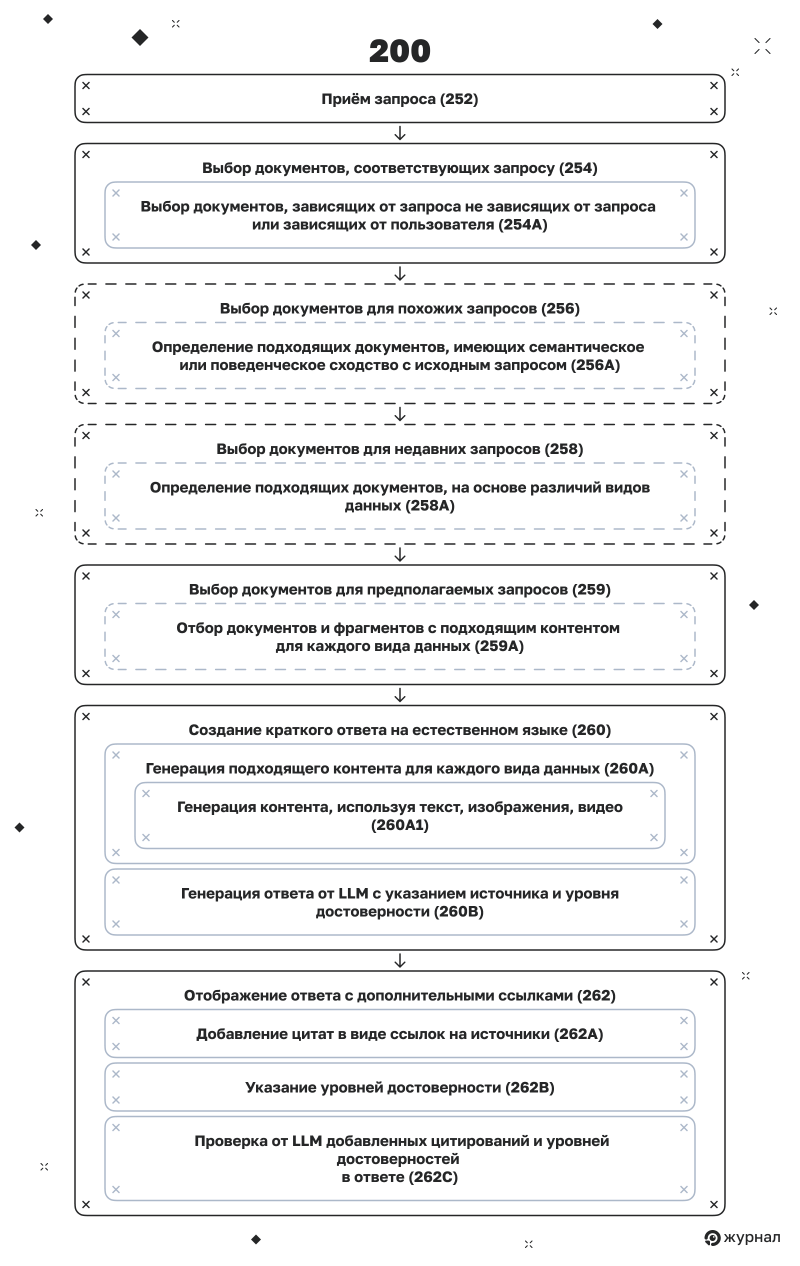
Шаг 1. Приём запроса (252)
Работает как и в предыдущем разделе.
Шаг 2. Выбор документов, соответствующих запросу (254)
Google извлекает набор документов, которые непосредственно соответствуют запросу пользователя. Эти документы выбираются на основе комбинации различных факторов, включая:
-
зависящие от запроса (точное соответствие тексту, семантическое сходство);
-
не зависящие от запроса (авторитетность документа, наличие внешних ссылок);
-
зависящие от пользователя (персонализация результатов).
Шаг 3. Выбор документов для похожих запросов (256)
Система определяет документы, соответствующие другим запросам, которые имеют семантическое или поведенческое сходство с исходным запросом. Эти документы добавляются в набор результатов поиска на основе их релевантности для связанных вариаций запроса.
Шаг 4. Выбор документов для недавних запросов (258)
Далее система выбирает документы для последних запросов, сделанных пользователем. Эти запросы могут отражать меняющиеся намерения или текущее поведение пользователя в процессе поиска.
С тактической точки зрения вам следует согласовать свою контент‑стратегию с концепцией «задач, которые нужно выполнить» (Jobs to be done).
Как разработать стратегию продвижения сайта для SEO: инструкция с примерами
Шаг 5. Выбор документов для предполагаемых запросов (259)
Наконец, система выбирает документы, соответствующие предполагаемым запросам. Эти запросы с возможным намерением генерируются в фоновом режиме.
Шаг 6. Создание краткого ответа на естественном языке (260)
После того как система соберёт все необходимые документы, она использует LLM для создания ответа. Этот процесс объединяет контент из текстовых и визуальных источников, а также может включать прямые цитаты из этих источников.
Шаг 7. Генерация ответа от LLM с указанием источника и уровня достоверности (260B)
Модель может присваивать отрывкам источники или указывать уровни достоверности определённых ответов в зависимости от того, насколько точно ответ соответствует найденным документам.
Шаг 8. Отображение ответа с дополнительными ссылками (262)
Окончательный результат выводится пользователю. Цитаты могут быть добавлены в виде ссылок на источники (262A). Также могут быть показаны уровни достоверности (262B), хотя только для внутренних целей. Результаты LLM и сравнение документов определяют, что будет цитироваться и насколько заметно.
Раскрытые алгоритмы Google. Как работает поисковая система согласно слитым документам
Вариант с изначальной генерацией
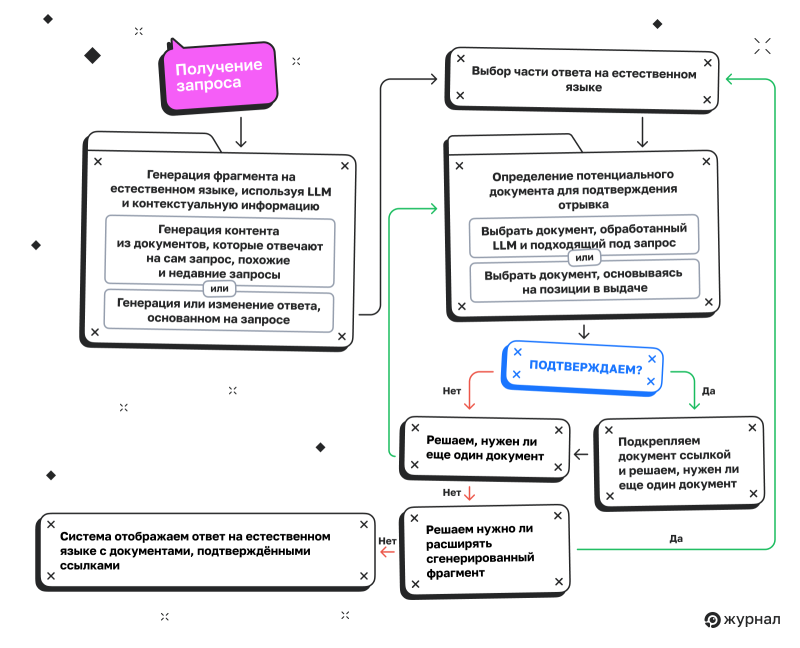
Система генерации кратких пересказов от ИИ, представленная на рисунке 3 в патенте, описывает архитектуру генеративного поиска и проверки. В этой версии сначала генерируется ответ, а затем сравнивается с исходной версией на основе результатов поиска. Процесс повторяется до тех пор, пока не будет получена проверенная версия ответа.
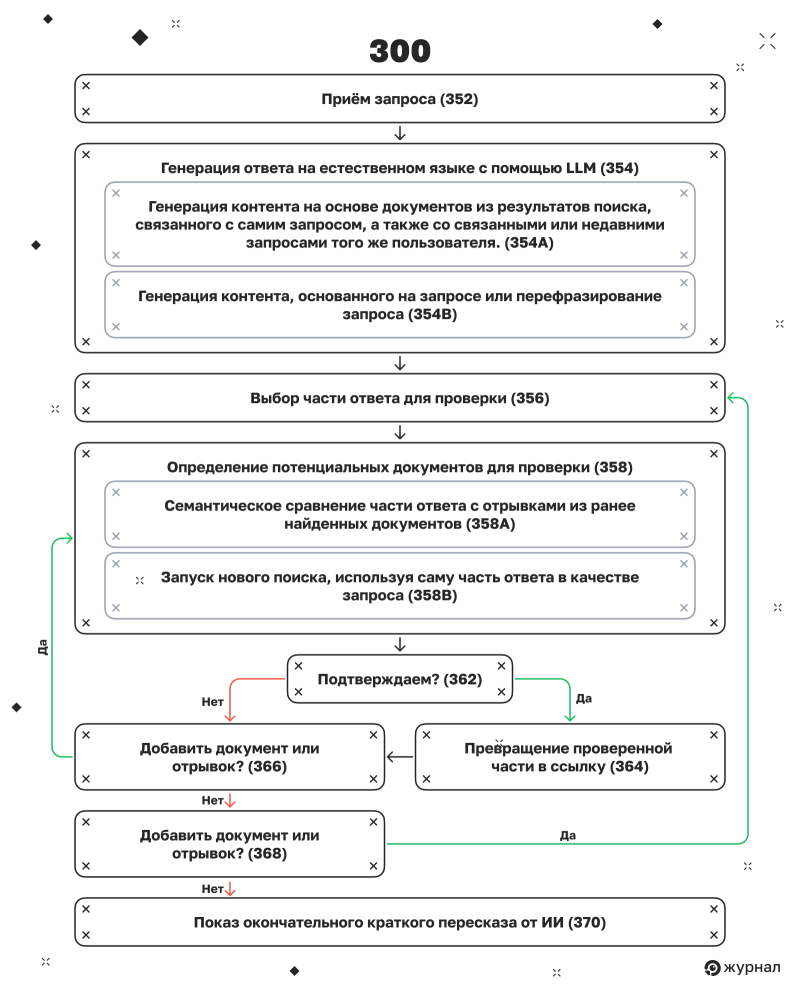
Давайте подробно рассмотрим этот процесс и его значение для SEO.
Шаг 1. Приём запроса (352)
Работает как и в предыдущем разделе.
Шаг 2. Генерация ответа на естественном языке с помощью LLM (354)
Система использует LLM для генерации ответа. Этот результат не просто извлекается из одного документа — он может быть синтезирован из контента, связанного с самим запросом, а также со связанными или недавними запросами того же пользователя. Кроме того, модель может использовать переформулировки исходного запроса, чтобы расширить объем ответа.
Шаг 3. Выбор части ответа для проверки (356)
После создания полного ответа система определяет отдельные сегменты или утверждения, которые необходимо проверить на основе фактических документов.
Шаг 4. Определение потенциальных документов для проверки (358)
Теперь системе нужно убедиться, что сгенерированное утверждение соответствует опубликованным материалам. Это можно сделать двумя способами:
1. Семантически сравнить часть ответа с отрывками из ранее найденных документов (358A).
2. Запустить новый поиск, используя саму часть ответа в качестве запроса (358B).
Шаг 5. Проверка пригодности потенциального документа (360)
Система сравнивает отрывок из документа‑кандидата со сгенерированной частью, чтобы понять, подтверждает ли он это утверждение. Здесь проверяется семантическое соответствие между ответом и содержимым документа.
Шаг 6. Вынесение решения (362)
Если проверка проходит успешно, система приступает к цитированию отрывка. Если же проверка не удалась, система пробует другой документ.
Шаг 7. Превращение проверенной части в ссылку (364)
Если отрывок подтверждается, соответствующий сегмент ответа связывается с помощью ссылки, которая направляет пользователя к подтверждённому источнику.
Шаг 8. Повторение для других отрывков и документов (366, 368)
Если в резюме содержатся новые, непроверенные отрывки, система повторяет процесс, чтобы также их идентифицировать и проверить.
Шаг 9. Показ окончательного краткого пересказа от ИИ (370)
После завершения проверки всех доступных частей (или, по крайней мере, тех, которые можно проверить), пользователь получает сгенерированный ИИ‑ответ со встроенными цитатами.
Как работает разветвление запросов в ИИ‑системе Google
Техника разветвления запросов — это секретный ингредиент, который лежит в основе кратких пересказов и режима ИИ в Google. Google создаёт серию так называемых синтетических запросов, основываясь на запросе, скрытых информационных потребностях и поведении пользователя.
Эти запросы используются для поиска документов, которые должны обосновать результаты. Хотя мы, вероятно, никогда не получим доступ к этим данным, Андреас Вольпини и автор исследования, которое вы читаете, независимо друг от друга создали два инструмента (1 и 2), которые помогают понять, какими могут быть эти запросы.
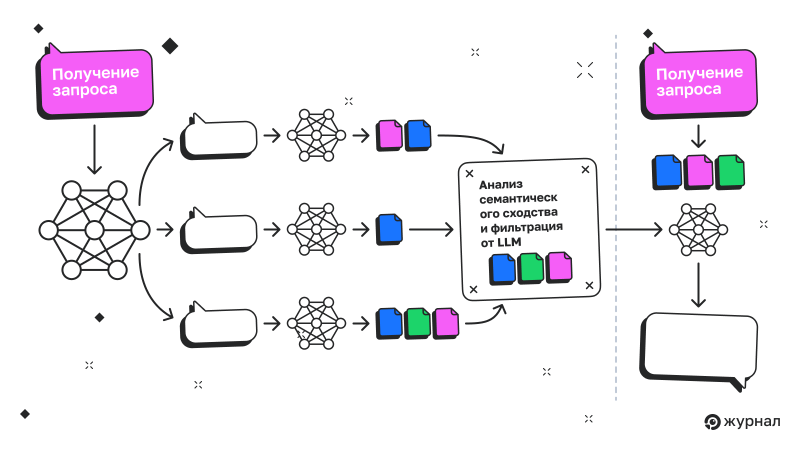
Эта схема, представленная в патенте «Системы и методы генерации на основе запросов для диверсифицированного поиска», демонстрирует, как Google обучает модель расширения запросов. В отличие от традиционного подхода к разветвлению ключевых слов, эта система задействует большие языковые модели для создания синтетических пар «запрос — документ».
Затем модель обучения поиску документов, которая может более глубоко понимать запросы пользователей, обучается на основе нескольких подсказок, генерируя разнообразные интерпретации интента.
Предыдущие патенты уже раскрывали некоторые аспекты этой технологии, но давайте подробно рассмотрим рабочий процесс обучения, шаг за шагом, и обсудим его значение для SEO на каждом этапе.

Шаг 1610. Получение запросов для поисковой задачи
Система начинает свою работу с получения как минимум двух запросов, описывающих задачу поиска, которую она должна решить. Эти запросы предоставляют большой языковой модели инструкции о том, как создавать варианты запросов, способных находить релевантный контент из заданного корпуса.
Шаг 1620. Создание синтетических пар «запрос — документ» с помощью LLM
Система использует LLM на основе подсказок и корпуса документов для создания синтетического набора данных для обучения. Каждая запись в этом наборе представляет собой пару: искусственно созданный запрос и соответствующий ему документ из корпуса. Это позволяет модели эффективно понять, какие типы вопросов может удовлетворить данный контент, даже если ни один пользователь никогда раньше не использовал подобный запрос.
Шаг 1630. Обучение модели на созданных парах
Модель обучается понимать взаимосвязи между синтетическими запросами и соответствующими документами. В результате мы получаем систему поиска документов, которая может принимать реальные запросы и определять, какие документы являются наиболее подходящими.
Шаг 1640. Внедрение обученной модели поиска
После завершения обучения модель становится поисковой системой, которая интегрируется, например, в краткие пересказы и режим ИИ. Она работает в фоновом режиме, принимая запросы пользователей и предлагая множество связанных, неявных, сравнительных и исторически релевантных запросов. Контент извлекается для каждого из них, а затем результаты объединяются в сгенерированный кластер.
Если ваш контент не будет появляться в результатах этих разветвлённых запросов, вы не будете цитироваться, даже если ваша страница в целом имеет высокие показатели.
Техника разветвления запросов сделает ваши усилия по оптимизации больше похожими на кампании по управлению репутацией. Поскольку внимание будет уделяться разнообразию источников для проверки информации, маркетологам придётся стремиться разместить свои сообщения на нескольких страницах и сайтах, чтобы Google обязательно обнаружил их контент, независимо от того, что именно ищет пользователь.
SERM: как управлять репутацией в сети
Память и персонализация на основе представлений о пользователях в режиме ИИ
Одной из самых интересных функций, которые Google активно внедряет в свой режим ИИ, является Личный контекст. В скором времени у вас появится возможность интегрировать большую часть ваших данных из экосистемы Google в поиск, чтобы получать более персонализированные ответы. Хотя стоит отметить, что эта функция вызывает много вопросов о конфиденциальности.
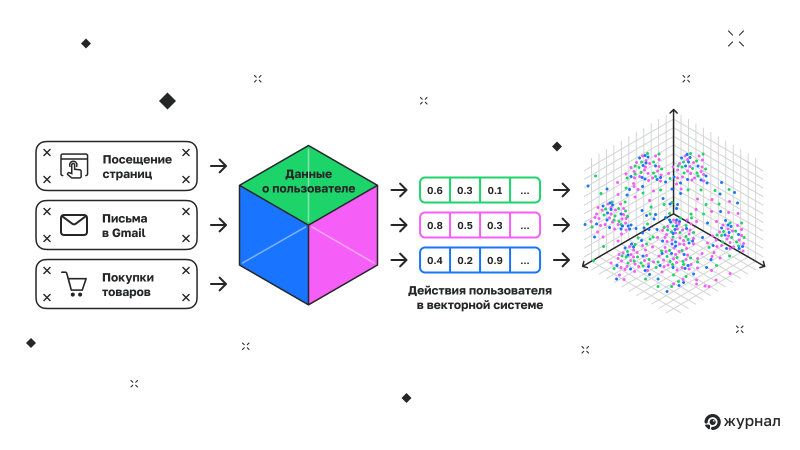
Схема, взятая из рисунка 4 патента «Модели встраивания пользовательских данных для персонализации последовательной обработки», демонстрирует, как системы Google, особенно в режиме ИИ, используют уникальный для каждого пользователя контекст, чтобы ответы на вопросы стали более персонализированными.
Вместо того чтобы анализировать каждый запрос как отдельный, эта система создаёт индивидуальный профиль для каждого пользователя, основываясь на его истории взаимодействия, предпочтениях и поведении. Этот профиль определяет, как режим ИИ интерпретирует запросы и ранжирует или генерирует ответы.
Давайте рассмотрим процесс более подробно, чтобы понять, как он влияет на SEO на каждом этапе.

Шаг 402. Сбор контекстных данных о пользователе
Система собирает разнообразные факторы, связанные с пользователем: его предыдущие поисковые запросы, взаимодействие с контентом, поведение при просмотре, клики, время, проведённое на странице, местоположение, тип устройства и многие другие.
Шаг 404. Генерация контекстуальных данных
Модель обрабатывает данные пользователя и создаёт векторное представление профиля этого пользователя. Это превращается персонализирующий фактор, который сопоставляется с входящими запросами.
Шаг 406. Получение инструкции (поискового запроса)
Система получает инструкцию по выполнению задачи. В режиме ИИ это обычно поисковый запрос от пользователя.
Шаг 408. Внедрение инструкции
Сам запрос также встраивается в систему с использованием отдельного векторного пространства. Теперь у системы есть два основных входа: контекстное внедрение данных пользователя и семантическое внедрение запроса.
Шаг 410. Объединение данных для создания персонализированных результатов
Система объединяет данные профиля пользователя и запросы. В результате этого определяется, какой контент будет извлечён или синтезирован. Конечный результат работы модели зависит именно от симбиоза двух типов данных. Ответ получается персонализированным на уровне рассуждений, а не только в процессе ранжирования.
Чтобы добиться успеха в AI Mode, ваш контент должен:
-
быть полезным для самых разных людей и ситуаций;
-
быть представлен в различных стилях и форматах;
-
поддерживать возможность генерации и повторного использования для сравнений, рекомендаций и других форматов.
Релевантность больше не определяется только соответствием запросу. Она также зависит от того, насколько хорошо подобран контент под мысли пользователя.
С появлением режима ИИ оптимизация контента по принципу «это подходит всем» ушла в прошлое, уступив место более персонализированному и фрагментированному поиску информации.
Обоснование в режиме ИИ у Google

Обоснование в LLM — это способность модели выходить за рамки простого сопоставления шаблонов и вместо этого применять многоэтапное логическое или дедуктивное мышление для достижения вывода. В отличие от простого извлечения или повторения информации, LLM, занимающаяся рассуждениями и обоснованиями, оценивает связи между концепциями, учитывает контекст, взвешивает альтернативы и только потом генерирует ответы.
Этот подход позволяет LLM отвечать на сложные вопросы, проводить сравнения, принимать решения или синтезировать информацию из нескольких источников подобно тому, как человек обдумывает проблему. ИИ от Google использует этот процесс, чтобы определить, какая информация должна быть использована в окончательном ответе.
Как работает обоснование в LLM от Google
Диаграмма на рисунке 7 из патента «Точная настройка моделей машинного обучения с помощью промежуточных рассуждений» демонстрирует процесс обучения моделей машинного обучения Google, включая LLM, которые обеспечивают работу кратких пересказов и режима ИИ. Она наглядно демонстрирует, как процесс обучения и оценки рассуждений происходит не только путём анализа окончательных ответов, но и благодаря обоснованиям промежуточных шагов, которые модель предпринимает для достижения этих ответов. Это также можно назвать протоколом или траекторией рассуждений.
Схема ниже очень важна для понимания того, почему SEO требует дальнейшего развития. Ниже мы подробно рассмотрим каждый шаг в процессе обучения рассуждению и его значение для SEO.
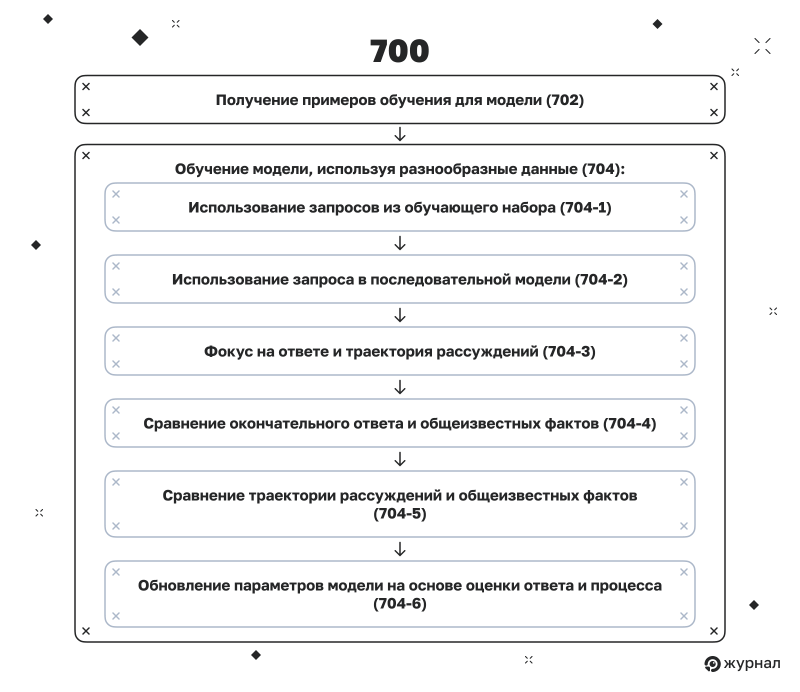
Шаг 702. Получение примеров обучения для модели последовательности
Система начинает с формирования разнообразного набора обучающих примеров. Эти пары запросов и ожидаемых результатов используются для обучения последовательной модели машинного обучения, какими являются LLM.
Шаг 704‑1. Использование запросов из обучающего набора
Для каждого примера в наборе данных модель получает запрос, который становится отправной точкой для цепочки рассуждений.
📉 Проверьте видимость своего сайта в Топвизоре
Узнать видимость сайта можно с помощью Проверки позиций в Топвизоре. Добавьте поисковые системы, регионы и запросы и запустите проверку, а также проверьте частоту запросов — она нужна для подсчёта видимости. Показатель рассчитается автоматически, а если у вас добавлены конкуренты, вы сможете сравнить с ними свою видимость на одном графике.
Шаг 704‑2. Использование запроса в последовательной модели
Запрос направляется в LLM, запуская прямой процесс, который завершается прогнозируемым ответом.
Шаг 704‑3. Фокус на ответе и траектория рассуждений
Модель не просто выдаёт ответ, она создаёт структурированную запись промежуточных шагов или скрытых решений, которые были использованы для его получения. Эти шаги могут включать выбор документа, оценку отрывка, извлечение фактов или последовательность дополнительных вопросов.
Шаг 704‑4. Сравнение окончательного ответа и общеизвестных фактов
Результат сравнивается с правильным ответом, который был дан человеком, чтобы понять, правильно ли модель получила ответ.
Шаг 704‑5. Сравнение траектории рассуждений и общеизвестных фактов
Даже если конечный ответ модели верен, также оцениваются шаги, которые она предпринимала для его достижения. Если модель следовала нелогичному, неэффективному или не соответствующему человеческому мышлению пути, она получает штраф, даже если результат оказался верным.
Шаг 704‑6. Обновление параметров модели на основе оценки ответа и процесса
Модель настраивается с учётом результатов обеих оценок. Это гарантирует, что она учится не только говорить, но и мыслить, как человек, осуществляющий поиск, или эксперт в данной области.
Как работает парное рассуждение в режиме ИИ
На рисунке 4 из патента «Метод ранжирования текста с помощью парного ранжирования» представлен алгоритм, который демонстрирует, как режим ИИ осуществляет дополнительное ранжирование на основе рассуждений, сравнивая пары отрывков друг с другом. Этот метод не опирается на традиционные модели оценки, такие как BM25 или простое векторное сходство, а использует LLM для оценки релевантности в контексте.
На практике это означает, что ваш контент не оценивается отдельно. Он оценивается в сравнении с другими фрагментами у конкурентов. И решение принимается генеративной моделью, которая приходит к выбору благодаря рассуждениям, а не простому поиску сходств.
Ниже представлен пошаговый рабочий процесс с описанием последствий для SEO на каждом этапе:

Шаг 402. Создание запроса и два варианта отрывков
Система генерирует промпт, который включает в себя запрос пользователя, первый отрывок (текст из первого документа) и второй отрывок (текст из другого документа). Эти фрагменты сформулированы таким образом, чтобы языковая модель могла оценить, какой из них более релевантен.
Шаг 404. Запрос LLM для сравнения
Этот запрос отправляется в генеративную модель обработки последовательностей (например, Gemini 2.5 или аналогичную). Модель обрабатывает запрос и оба фрагмента‑кандидата и должна сравнить их на основе семантики.
Чтобы пройти проверку, ваш отрывок должен соответствовать следующим критериям:
-
чётко и ясно описывает, кто, что, почему и как;
-
обладает богатым контекстом, но не перегружен деталями;
-
организован в естественном и разговорном стиле.
Важными инструментами здесь выступают заголовки и форматирование. Также рекомендуется использовать сильные вступительные предложения, которые чётко выражают ценность вашего контента.
Шаг 406. Проведение парного сравнения между отрывками
LLM оценивает, какой из двух предложенных отрывков лучше отвечает запросу пользователя. Для этого он может использовать как собственную логику, так и заранее обученные методы, основанные на результатах тонкой настройки.
Значение для SEO: модель не просто считает баллы, она выносит вердикты. Представьте, что это редакционный процесс, в котором наш контент оценивается придирчивым критиком. В таких условиях расплывчатые или общие тексты получают низкие оценки. Чтобы выиграть в этой игре, нужно предоставлять понятный контент, основанный на фактах.
Как провести анализ контента сайта
Шаг 408. Вынесение решения о ранжировании
Модель предлагает решение о том, какой из двух отрывков следует поставить выше в поисковой выдаче для данного запроса. Это решение может использоваться дальше в качестве прецедента для определения того, какой контент следует включить в процессе синтеза.
Сравнение функциональности режима ИИ и кратких пересказов от ИИ
Задачи кратких пересказов от ИИ и режима ИИ во многом схожи. Эта таблица — ориентир, который поможет понять различия между этими двумя инструментами.
|
Функциональность |
Краткие пересказы от ИИ |
Режим ИИ |
|
Когда срабатывает |
Автоматически появляется при определённых запросах в поиске Google |
Активируется, когда пользователь вводит поисковый запрос в разделе «Режим ИИ» |
|
Как выглядит для пользователя |
Встроен в традиционную выдачу; дополняет стандартные органические списки |
Полноэкранный ИИ‑интерфейс; заменяет выдачу интерактивным интерфейсом, похожим на агента |
|
Как разветвляются запросы |
Выполняется ограниченное внутреннее расширение, чтобы облегчить процесс создания сводных данных |
Осуществляет широкое разветвление запросов с учётом скрытых намерений и нескольких типов синтетических запросов |
|
Подход к извлечению контента |
Извлекает документы‑кандидаты через стандартный поисковый индекс с дополнительной оценкой от LLM |
Использует алгоритм сжатого поиска и парное ранжирование на основе данных о пользователе с LLM |
|
Единица извлечения контента |
Полные документы с кратким изложением основных моментов |
Отдельные фрагменты или блоки, оптимизированные для поиска и цитирования |
|
Метод цитирования |
Цитаты встроены в фрагменты текста (ссылка на текст при прокрутке или встроенные ссылки) |
Цитаты выбираются по соответствию этапам рассуждений, а не обязательно по рейтингу |
|
Рассуждение и формирование ответов |
Использует экстрактивное и абстрактное резюмирование с помощью LLM |
Составная аргументация по отрывкам с использованием генерации цепочки мыслей |
|
Персонализация |
Минимальная персонализация, кроме местоположения и прошлых запросов |
Использует векторные данные пользователя, информацию об устройстве и историю прошлых взаимодействий |
|
Мультимодальность |
Информация представлена в текстовом виде с ссылками. Возможно, в тексте могут быть использованы скрытые видео и изображения |
Естественная поддержка синтеза различных типов данных (текст, изображения, видео, аудио, структурированные данные) |
|
Критерии релевантности цитирования |
На основе ранжирования источников и значимости в ответе |
На основе того, насколько прямо отрывок соответствует рассуждению или ответу (согласно US20240362093A1) |
|
Вид ответа |
Статичные блоки ответов с цитатами, часто в виде списка или краткого текста |
Динамический интерактивный интерфейс (карточки, диаграммы, таблицы, агенты), который адаптируется к типу запроса |
|
Источники |
Обычно извлекаются из документов с самым высоким рейтингом по органическим результатам поиска из ограниченного набора синтетических запросов |
Может включать документы, не входящие в верхнюю часть поисковой выдачи, на основе широкого набора синтетических запросов, отобранных по схожести и релевантности |
Выводы
Это больше не то же SEO, что и раньше
В SEO‑сообществе существует убеждение, что оптимизация для кратких пересказов, режима ИИ или прочего не является чем‑то новым. Они утверждают, что это всего лишь разновидность SEO. Но здесь прослеживается та же устаревшая логика, которую мы видели в бесконечных спорах о поддоменах или в дискуссиях о 301‑м и 302‑м редиректах. Однако этот спор имеет более серьёзные последствия, потому что это не просто техническое разногласие. Это упущенная возможность переосмыслить всю ценность поиска.
Мы находимся на пороге настоящей революции. Впервые за десятилетия у нас есть возможность переосмыслить ценность поиска как такового. Однако в наших рядах мы склонны преуменьшать его значимость, пытаясь втиснуть в рамки дисциплины, которая десятилетиями формировалась на основе невысоких ожиданий и противоречивых стимулов.
Эту уникальную возможность не стоит игнорировать в пользу защиты устаревших представлений и страха потерять свою квалификацию.
Технически это можно было бы включить в сферу SEO. Мы уже поступали так раньше. Фактически мы делаем это каждый раз, когда Google пытается манипулировать нашим сообществом в своих целях. Но делать то же и сейчас было бы огромной стратегической ошибкой.
Споры о сути изменений упускают из виду важный момент
ИИ привлекает внимание всего мира. Диалоговые интерфейсы становятся новым способом доступа к информации. И эти новые возможности в значительной степени не используются в качестве маркетингового канала.
Между тем SEO уже обременено стереотипами. В глазах топ‑менеджмента SEO рассматривается как канал для сокращения затрат. Его связывают с «бесплатным трафиком». Иронично, но именно это представление, сформулированное теми, кто превратил его в главный источник переходов в интернете, подорвало нашу способность получать бюджеты, людей и внимание, соответствующие создаваемой нами ценности.
Мнение «это всего лишь SEO» не просто не учитывает все нюансы. Оно усиливает ограничения, которые сдерживали развитие этой области на протяжении многих лет. Этот подход заставляет нас зацикливаться на устаревших показателях эффективности, в то время как нам необходимо занять место за столом переговоров, где формируется будущее доступа к информации.
Перелом: как изменится интернет с появлением ИИ
Что делать? Учиться в других сферах
Есть ещё одна алгоритмическая сфера, где контент так же важен. Она непредсказуема, её сложно оценить, и редко кто ожидает, что она принесёт результаты в первый же день. Однако руководство компаний не нуждается в прогнозах, они просто продолжают вкладывать туда деньги.
Что такое маркетинг в социальных сетях? По сути, это контент‑стратегия, адаптированная для этой сферы. Но специалисты по социальным сетям не ограничились только разработкой контента. Они дали ей название, и благодаря этому руководство выделяет туда бюджеты. Они наделили её полномочиями, и она стала самостоятельной категорией. Мы можем и должны применить тот же подход к поиску.
39 соцсетей для обратных ссылок, которые помогут повысить рейтинг сайта в 2025 году
Всё это вопрос восприятия
А восприятие определяет инвестиции. Если мы будем продолжать называть SEO «всего лишь SEO», то рискуем остаться недооценёнными, недофинансированными и непонятыми. Это особенно важно в эпоху, когда видимость и даже сами клики становятся абстракциями за генеративными интерфейсами.
Ещё по теме
16 компаний в ТОПе Google в 2024 году: кто они и как им это удаётся
Люди, которые разрушили интернет: хлёсткий очерк о гигантах SEO‑индустрии