
Это большой гайд о сущностном SEO. В нём Виктор Прядильщиков, SEO Team Lead WSS, рассказывает, с чего всё началось, как работает и почему отказ от ключевого подхода — важный шаг в продвижении сайтов.
Переход от ключевых слов к сущностям: новая парадигма SEO
Ещё недавно SEO держалось на ключах — словосочетаниях, по которым пользователи ищут информацию. Оптимизаторы подбирали фразы из этих словосочетаний и добавляли их в нужные места текста.
💼 Один сервис для всех задач по семантике
Собирайте семантическое ядро, расширяйте его с помощью подсказок и ключевиков конкурентов, проверяйте частотность и кластеризуйте группы запросов на основе ТОП‑10. Всё, что нужно для управления семантикой, доступно онлайн в Топвизоре.
Но у такого подхода был минус: поисковики могли не понимать, какой смысл стоит за словом. Например, Apple может означать и компанию, и фрукт. Поисковикам приходилось угадывать намерение пользователя по ограниченному набору слов.

В 2010‑х, когда появилась обработка естественного языка (NLP) и машинное обучение, появился и семантический поиск. Алгоритмы вроде Hummingbird, RankBrain и BERT позволили Google больше не полагаться на совпадения слов. Современная концепция рассматривает Apple как сущность — уникальный объект со своими связями и характеристиками. Это может быть или бренд, или фрукт, но его в любом случае можно однозначно идентифицировать.

SEO эволюционировало от подсчёта плотности ключевых слов к оценке релевантности и глубины контента. Это один из самых значимых поворотов в индустрии: оптимизируя не под набор букв, а под смысл, SEO‑специалисты говорят с поисковой системой на одном языке.
Что такое сущности и почему они важны
В SEO сущность — это любой определяемый объект или понятие. Люди, места, организации, продукты, события, идеи — всё, что можно чётко обозначить. Важно понимать: ключевые запросы — это просто строки текста, а сущность — это единица информации с облаком связей вокруг.
Например, «Нью‑Йорк» как слово имеет несколько значений. Но как сущность в базе знаний Google он будет храниться с указанием конкретики: «Нью‑Йорк город» или «Нью‑Йорк штат» — каждый с уникальными идентификатором и связями. Благодаря этому поисковик понимает, что пользователь, вводящий запрос «best pizza places New York», имеет в виду город Нью‑Йорк (сущность‑место), а не штат или что‑либо ещё.

Сущности важны тем, что они несут контекст. У каждой есть сеть связанных понятий. Сущность «Стив Джобс» связана с Apple, Pixar, iPhone. Когда пользователь ищет его, Google подтягивает из базы не только факты о Джобсе, но и связанные сущности: фильмы, цитаты, компании.
Почему сущности важны для SEO
Одно из их главных преимуществ сущностей — точное считывание поискового намерения (интента): система видит смысл за словами и выдаёт контент, который его закрывает. Пользователь может написать одно, а иметь в виду совсем другое — и алгоритм это считывает.
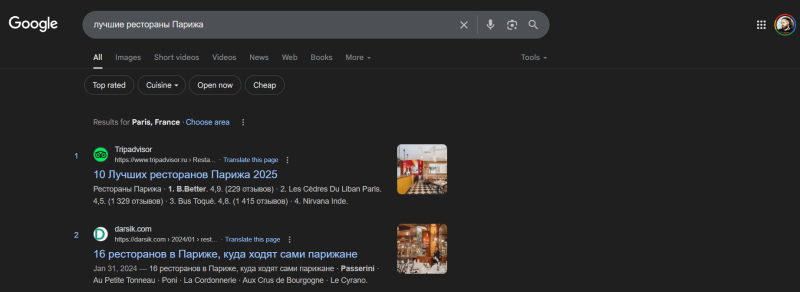
Например, пользователь вводит запрос «лучшие рестораны Парижа». Явных сущностей может не быть, но поисковик понимает: речь идёт о месте «Париж», категории «ресторан» и концепции «рейтинг лучших». На основе этого он показывает подборки заведений, карты и отзывы. Если бы алгоритм просто искал страницы по словам «лучшие» + «рестораны» + «Париж», результат был бы куда менее точным.

Кроме того, сущностный подход усиливает релевантность контента. Страницы, оптимизированные под сущности, глубже покрывают тему.
Чем богаче сеть связанных сущностей, тем выше шанс, что страница закроет разные поисковые запросы — даже без точных совпадений. Особенно заметно это в голосовом поиске. Там запросы звучат естественно: «где поесть суши рядом» или «какая река длиннее — Волга или Дон». Контент, построенный по сущностям, лучше решает такие задачи. В итоге пользователь без лишних кликов получает ответ — это повышает удовлетворённость и поведенческие метрики.
Как ПФ влияют на SEO в Яндексе и Google
Как поисковики распознают сущности
Процесс можно разделить на два этапа: распознавание сущностей (какие объекты или понятия упоминаются) и использование знаний о сущностях при ранжировании результатов.
Google и другие поисковые системы формируют базу знаний сущностей двумя способами:
-
Из авторитетных источников. Алгоритмы используют уже существующие базы данных: прежде всего Википедию, которая стала основой первой Knowledge Graph, запущенной в 2012 году, а также Wikidata, IMDb, Britannica и другие справочники. Там поисковик находит проверенные сущности и их свойства.
-
Из веб‑документов. Новые сущности появляются быстрее, чем успевают обновляться базы данных. Поэтому поисковики научились находить их в неструктурированных данных.
Чтобы выявить новую сущность, поисковики анализируют контекст. Если имя человека часто встречается рядом с известной организацией, которая уже является сущностью, алгоритм делает вывод, что перед ним новая значимая сущность. Например, если во множестве публикаций повторяется связка «Артём Паклонский — сооснователь агентства WSS», алгоритм понимает, что Артём — отдельная сущность и пора бы внести его в базу.
Есть и оценка значимости: стать сущностью в узкой нише проще, чем в широкой. Местный эксперт может считаться сущностью внутри своей ниши или региона, даже если в отрасли его имя почти не известно.
После идентификации сущность получает место в базе знаний и уникальный идентификатор (Entity ID). Каждая сущность хранится структурированно. Ей присваиваются:
-
имя;
-
Entity ID — внутренний код, который отличает одноимённые объекты, например город Москва и киностудия «Москва»;
-
классы (categories) — типы вроде «компания», «организация», «технологическая фирма»;
-
атрибуты (properties) — даты, числа, описания; для человека это дата рождения и профессия, для фильма — год выхода, режиссёр, кассовые сборы.
Ещё один важнейший элемент — отношения (relationships), то есть связи между сущностями: кто чем владеет, где находится, с кем связан. Эти связи формируют граф знаний — сеть узлов и линий, которая отражает устройство мира в терминах Google.

Как сущности влияют на алгоритмы ранжирования
Распознав сущности и связи в контенте, поисковая система использует эту информацию для оценки релевантности и ранжирования страниц. Хотя Google не раскрывает полностью, как именно учитываются сущностные факторы, патенты и эксперименты указывают на ряд важных моментов.

Сущности не отменяют классические подходы в SEO. Ключевые слова по‑прежнему важны: они задают тему. Сущности помогают находить связи между темами и уточняют контекст. Без обратных ссылок сайт не вырастет, но важен не только сам факт ссылки, но и сайт, на котором она расположена. Чем ближе донор к вашей тематике, тем весомее ссылка, а оценить степень близости помогают сущности.
Для SEO‑специалистов это означает, что сайты, которые понятны поисковику на уровне сущностей и их связей, получают преимущество. Их контент выглядит для алгоритмов осмысленным, структурированным и экспертным, а это влияет и на позиции в выдаче.
Роль структурированных данных в сущностном SEO
Правильно понять содержимое страницы поисковикам помогает не только хорошо написанный текст, но и структурированные данные. Это специальная разметка в коде, которая явно указывает на сущности и детали, обычно это формат Schema.org/JSON-LD.
Во‑первых, разметка Schema.org позволяет задать типы сущностей. Например, статья об известном человеке может содержать тип Person, чтобы обозначить, что это слово — это персона, с полями вроде birthDate для даты рождения.
Если вы ведёте корпоративный блог, можно разметить название компании как Organization и добавить ссылку (sameAs) на профиль в Википедии или другие официальные страницы. Так вы свяжете вашу организацию с известной сущностью в базе знаний. Всё это облегчает алгоритму задачу идентификации.
Во‑вторых, структурированные данные — частое условие для попадания в расширенные блоки выдачи: knowledge panel о бренде или личности, rich snippets с рецептами, рейтингами, FAQ.
Правильно заданные сущности через Schema.org не только помогают алгоритму понять страницу, но и подсказывают, какую дополнительную информацию можно показать пользователю. Если разметить страницу с мероприятием с помощью event (дата, место проведения), есть шанс попасть в блок событий в выдаче. А разметка FAQ добавит под вашим сниппетом список вопросов и ответов. Такие элементы улучшают видимость сайта, повышают CTR и косвенно влияют на трафик.
Важно и то, что структурированные данные формализуют отношения между сущностями внутри страницы. В карточке товара можно указать: этот товар (product) произведён такой‑то организацией (organization) и имеет такие‑то отзывы (review by person). Так формируется мини‑граф связей прямо в коде, который алгоритм читает и точнее интерпретирует.
Главное — не ошибаться в разметке. Среди типичных ошибок — дублирование одной и той же схемы на всех страницах и использование нерелевантных типов. А ещё данные должны соответствовать содержимому: нельзя отмечать несуществующие элементы или злоупотреблять Schema в обход правил. За это можно получить санкции, например наказание от Google за misleading markup.
Но если разметка внедрена правильно, выгода очевидна: вы фактически даёте поисковику чертёж сущностей и их свойств, упрощая семантический разбор контента.
Как создавать контент, ориентированный на сущности
Сфокусируйтесь на тематическом охвате и смысловой связности материалов. Разберёмся в ключевых принципах такого подхода.
Идентифицируйте ключевые сущности темы
На этапе исследования выделите, какие объекты связаны с вашей нишей: персоны, компании, продукты, технологии, понятия. Для кулинарного сайта это блюда, ингредиенты, повара, кухни мира. И вместо бездумно собранных тысяч ключевых слов у вас получится «карта» сущностей — вы будете знать, о чём действительно важно рассказывать.
Стройте контент‑хабы вокруг сущностей
Эффективная практика — формировать на сайте контентные кластеры: одна страница раскрывает тему в целом, а рядом — поддерживающие материалы по подтемам. Эти страницы связаны внутренними ссылками и вместе раскрывают сущность или группу сущностей.
Что такое внутренняя перелинковка и как её сделать
Например, статья «Что такое блокчейн» (сущность «блокчейн») соединена с материалами «Применение блокчейна в финансах», «История технологии», «Плюсы и минусы». Все они ссылаются друг на друга и создают для поисковика чёткий кластер. Такой подход демонстрирует экспертность и полноту охвата темы и положительно сказывается на ранжировании.
Учитывайте интент пользователей
Подумайте о различных типах запросов, которые пользователи задают по вашей теме. Кроме информационных статей, нужно создавать разделы FAQ, глоссарии терминов, руководства «Как сделать…». Вопросные запросы вроде «Как настроить…» или «В чём разница между…» часто напрямую связаны с сущностями. Если вы включите ответы на них в ваших материалах, то сможете лучше охватить поисковый спрос.
Как собрать вопросы и ответы (FAQ) для сайта, которые приведут трафик и лиды
Используйте варианты и синонимы
Одна сущность может упоминаться разными словами: Санкт‑Петербург, СПб, Питер. Включайте альтернативные названия в текст: все аббревиатуры, переводы, локальные наименования, когда это уместно. Так контент покажет свою релевантность разным запросам, связанным с одной сущностью. Главное — делать это естественно: например, «Санкт‑Петербург (он же Питер) славится архитектурой…» Не превращайте текст в список синонимов.
Обновляйте и расширяйте материалы
Сущности могут эволюционировать: появляются новые факты, события, детали. Поэтому важно регулярно актуализировать материалы на вашем сайте, пересматривать и дополнять страницы. Этим вы показываете поисковикам, что ресурс поддерживается, и улучшаете свой тематический авторитет.
Как провести анализ контента сайта
Что ещё почитать об изменении в поисковой оптимизации 👇
Забудьте всё, что вы знали о Google: как отказ от &num=100 разделил жизнь на «до» и «после»
Как работают AI Mode и AI Overviews и почему нам необходимы новые SEO‑стратегии — на основе патентов
Статистика CTR в Google — отчёт об изменениях за II квартал 2025 года